作为一个 UBMC 零基础小白,本来还在新手村捡木棍,结果一脚踏进了 openUBMC 的大地图。趁着 LTS 版本发布前,我给自己安排了一个“主线任务”:顺着工具链一路追踪 build 流程。
为了把这条流水线看得更清楚,我在代码里塞了大量探针,基本属于“到处打点、逮住就问你是谁”的程度 ![]() 。这篇帖子就当是我追踪过程的复盘笔记,一方面给后来者留个路标,另一方面也欢迎各位大佬指正(轻喷)。
。这篇帖子就当是我追踪过程的复盘笔记,一方面给后来者留个路标,另一方面也欢迎各位大佬指正(轻喷)。
全程 是参照下方教程实现的Vim 跳转 ,增加探针链路追完大概花了 1.5 天,亲测基本上跳转无误,用的也是开源社区最受欢迎的fzf以及协同tselect。
跨文件/跨语言(py / lua / yml)无缝联动。支持 tselect 与 fzf 双路跳转、代码结构预览与快速检索。
综述 / 跳转导览(bingo)
本文给出从系统入口到 create_target_scheduler('personal') 的最短跳转路线,配合截图与探针日志做到“一步一锚点、可复现”。其后涉及的实际执行(由 start 启动子执行单元跑各 work)此文不展开。
/usr/local/bin/bingo
→ bmcgo.bmcgo.run(args)
→ bmcgo.cli.cli.main(args) → bmcgo.cli.cli.run(args)
→ Command.run(argv)
→ [method 分发]
valid_command='build'
return method(command_args)
≡ return Command.build(command_args) ← 跳不过去就直接搜 `def build(`
→ Command.build(argv)
→ Command.frame_build(argv)
→ Frame.parse(args, ext_targets_dir)
→ Frame.run()
→ create_target_scheduler('personal', ..., target=.../target/personal.yml)
→ (其后由 `start` 启动子执行单元执行各 work,本文不展开)
阅读方式(极简):
-
每到一个锚点配一张“跳转截图”;遇到 method 跳不过去,按上面等价式直接搜
def build(。 -
日志对齐要点:
RESOLVED COMMAND build→PATH = B (METHOD)→DISPATCH → frame_build→TARGET YAML OPEN → personal.yml→==== SUBWORKS TREE (TOP) ==== / tasks.total = …(此处为递归打印/计数,用于预览,不是执行循环)。
bingo 命令入口:/usr/local/bin/bingo
bingo 安装完成后,系统里会多出一个可执行文件:
which bingo
# /usr/local/bin/bingo
把这个文件用 Vim 打开,可以看到它其实只是一个很薄的 Python 启动脚本:
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import re
import sys
from bmcgo.bmcgo import run
if __name__ == '__main__':
# 兼容 pip 安装生成的入口脚本,把结尾的 -script.pyw / .exe 去掉
sys.argv[0] = re.sub(r'(-script\.pyw|\.exe)?$', '', sys.argv[0])
# 真正的入口在 bmcgo.bmcgo.run()
sys.exit(run())
这段代码做的事情非常简单:
-
通过
#!/usr/bin/python3声明用 Python3 解释执行; -
导入
bmcgo.bmcgo模块中的run()函数; -
在
__main__分支里,对sys.argv[0]做一次正则替换(去掉可能存在的-script.pyw或.exe后缀),这是 pip 生成入口脚本时的一个通用套路; -
最后调用
run(),并把返回值作为进程的退出码返回给系统。
也就是说:
命令行里的
bingo本质上就是在调用bmcgo.bmcgo.run()。
下面这张图展示的是我在 Vim 中通过 tags/fzf 跳转到 run 定义的位置,作为后续分析调用链的起点:
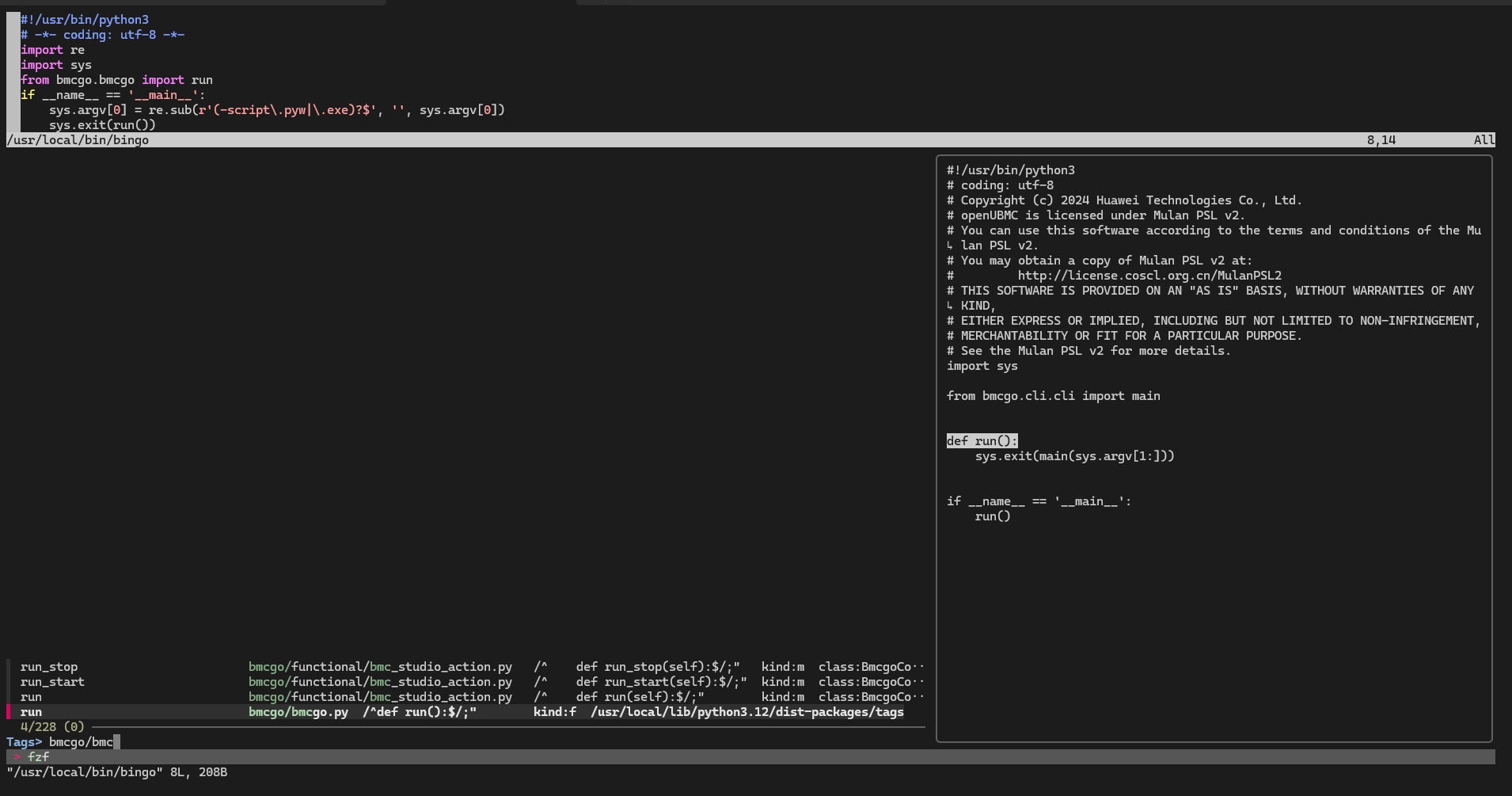
(上图中左侧是 tags/fzf 搜索到的各个 run 符号,右侧是 /usr/local/bin/bingo 启动脚本本身。)
2. 从 bmcgo.bmcgo.run() 继续追到 CLI 入口
在上一节我们看到,/usr/local/bin/bingo 只是调用了 bmcgo.bmcgo.run()。 使用代码跳转功能(如 Vim 里对 run 按 CTRL-]),可以直接跳到下面这个文件:
#!/usr/bin/python3
#省略xxx
#xxxx
import sys
from bmcgo.cli.cli import main
def run():
# 把命令行参数(去掉程序名)交给 CLI 模块的 main()
sys.exit(main(sys.argv[1:]))
if __name__ == '__main__':
run()
这层代码的作用非常“薄”,主要就是两件事:
-
导入真正的 CLI 入口:
from bmcgo.cli.cli import main可以看出,后续所有子命令解析、任务分发的核心逻辑,其实都集中在
bmcgo.cli.cli.main()里。 -
转发命令行参数并退出:
def run(): sys.exit(main(sys.argv[1:]))-
sys.argv[1:]:丢掉程序名,只把用户输入的参数(如build -b openUBMC)传给main(); -
sys.exit(...):将main()的返回值作为进程退出码返回给操作系统。
-
到这里,我们已经完成了第二次“跟踪跳转”:
bingo→bmcgo.bmcgo.run()→bmcgo.cli.cli.main()。
接下来,只需要在编辑器里继续对 main 做一次代码跳转(例如在 from bmcgo.cli.cli import main 上按 CTRL-]),就可以进入 CLI 层的真正入口函数,看到 bingo 是如何解析子命令、选择对应 task 的,这也是后面整个“代码跳转解析工具链”要重点讲解的部分。
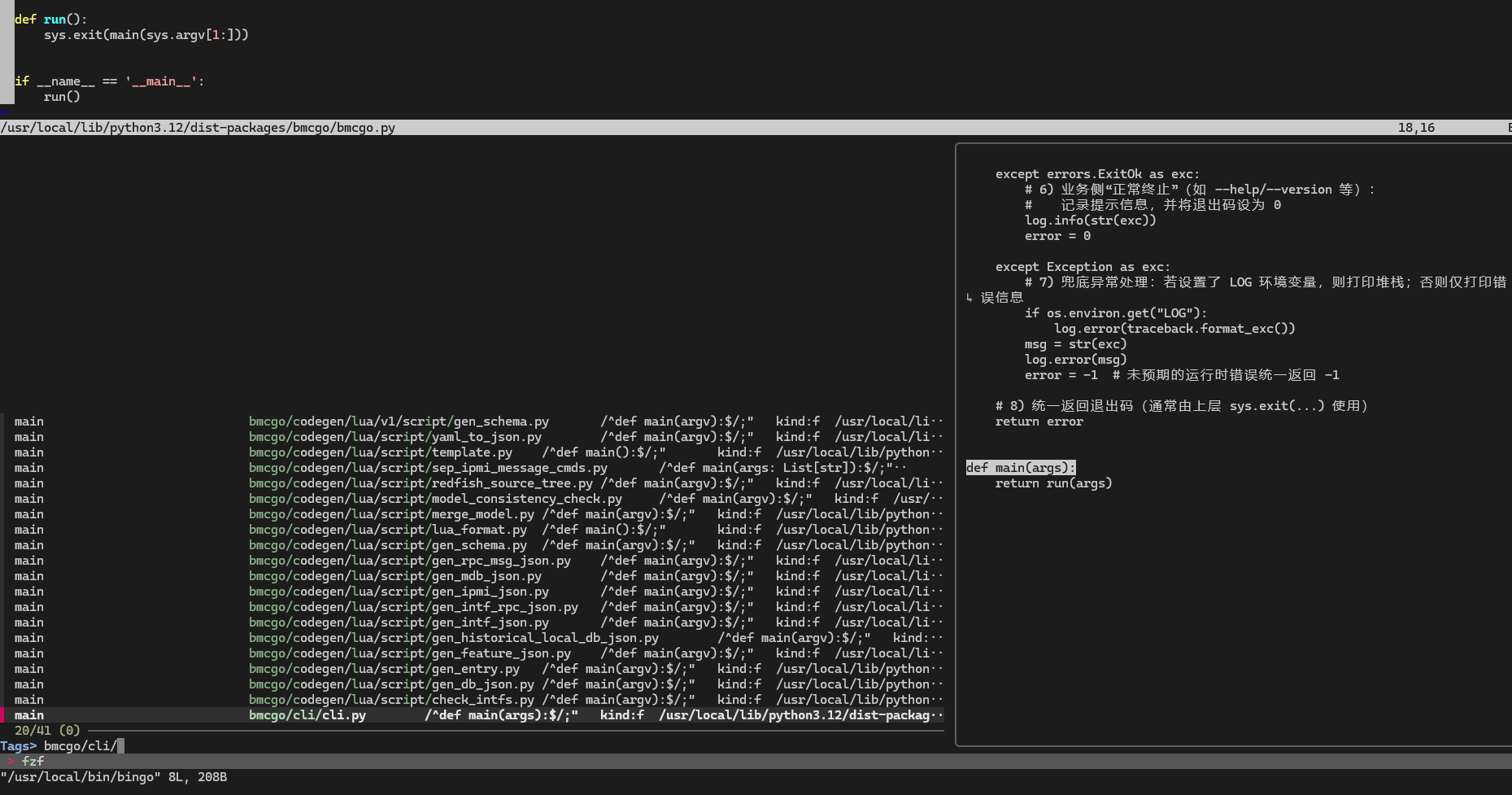
图 使用代码跳转从
/usr/local/bin/bingo追踪到bmcgo/bmcgo.py,可以看到run()只是简单调用bmcgo.cli.cli.main()。
CLI 总入口:bmcgo.cli.cli.main() / run()
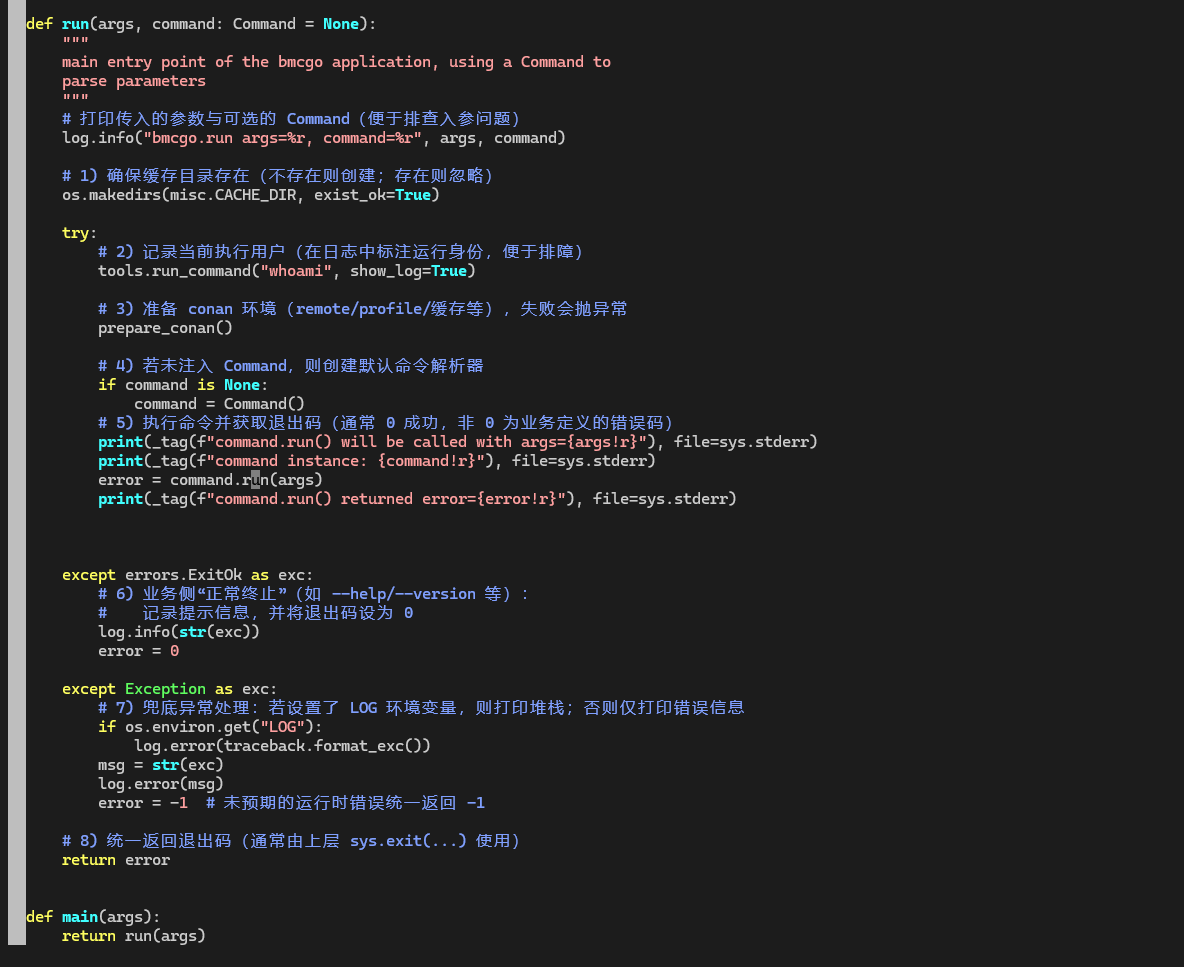
在上一节我们已经到了 bmcgo.bmcgo.run()。 继续代码跳转,可以看到 bmcgo/cli/cli.py 里有:
def main(args):
return run(args)
也就是说,真正干活的是 run(args, command=None),main() 只是一个薄封装,给外层 sys.exit(main(sys.argv[1:])) 调用用的。
run() 的职责可以一句话概括:
准备好运行环境,然后把命令行参数交给
Command.run()处理,最后返回退出码。
具体做了几件事
-
记录入参 把收到的
args和command写到日志里,方便之后排查“到底收到了什么命令”。 -
准备工作目录 创建/检查一个缓存目录(
misc.CACHE_DIR),后面的一些功能会往这里写中间文件。 -
准备 Conan 环境 调用
prepare_conan()。 -
创建
Command对象 如果没有从外面注入command,就自己command = Command()。这个对象里包含了所有子命令(build、deploy 等)的解析和分发逻辑。 -
真正执行命令:
error = command.run(args)这一句是核心跳转点:-
Command.run()会解析args,判断你是执行build还是其他子命令; -
再选出对应的 Task 类(比如
BuildTask),最后调用具体任务的run()。
-
-
处理“正常退出”场景 如果内部抛出了一个叫
ExitOk的异常(典型是--help、--version这种),这里会把它当成“正常结束”,退出码统一设为0。 -
兜底异常处理 其他没预料到的异常会在这里统一处理:
-
打一条错误日志(如果开了调试环境变量,就顺便把堆栈也打出来);
-
返回一个固定的错误码,比如
-1,表示“程序本身出错”。
-
-
返回退出码
run()最后返回的数字,会被外层sys.exit(...)用掉,变成 shell 里看到的$?。
用探针 + build 命令确认调用链
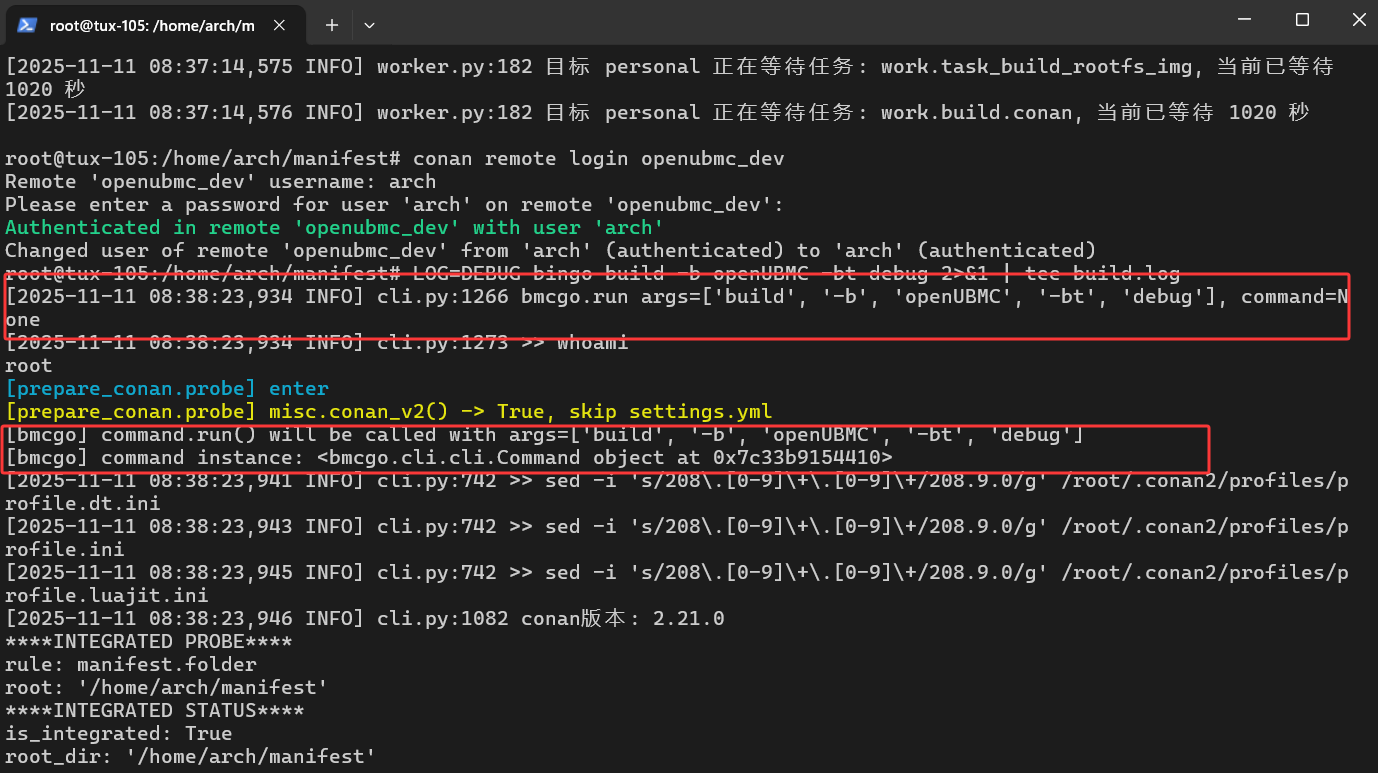
为了写这份教程,我在 run() 里前后加了几行简单的打印(这些不在原始源码里,只是临时加的探针),然后执行了一次:
bingo build -b openUBMC -bt debug
从终端输出可以看到两件事情:
-
bmcgo.run args=[...]这样的日志,说明命令行参数已经正确传到了run(); -
接着能看到类似“将要调用 command.run(…)”以及“命令实例是什么”的输出,说明确实是从这里跳进
Command.run()的。
这些探针只是用来验证调用顺序:
bingo → bmcgo.bmcgo.run → bmcgo.cli.cli.main → bmcgo.cli.cli.run → Command.run → 具体 Task。
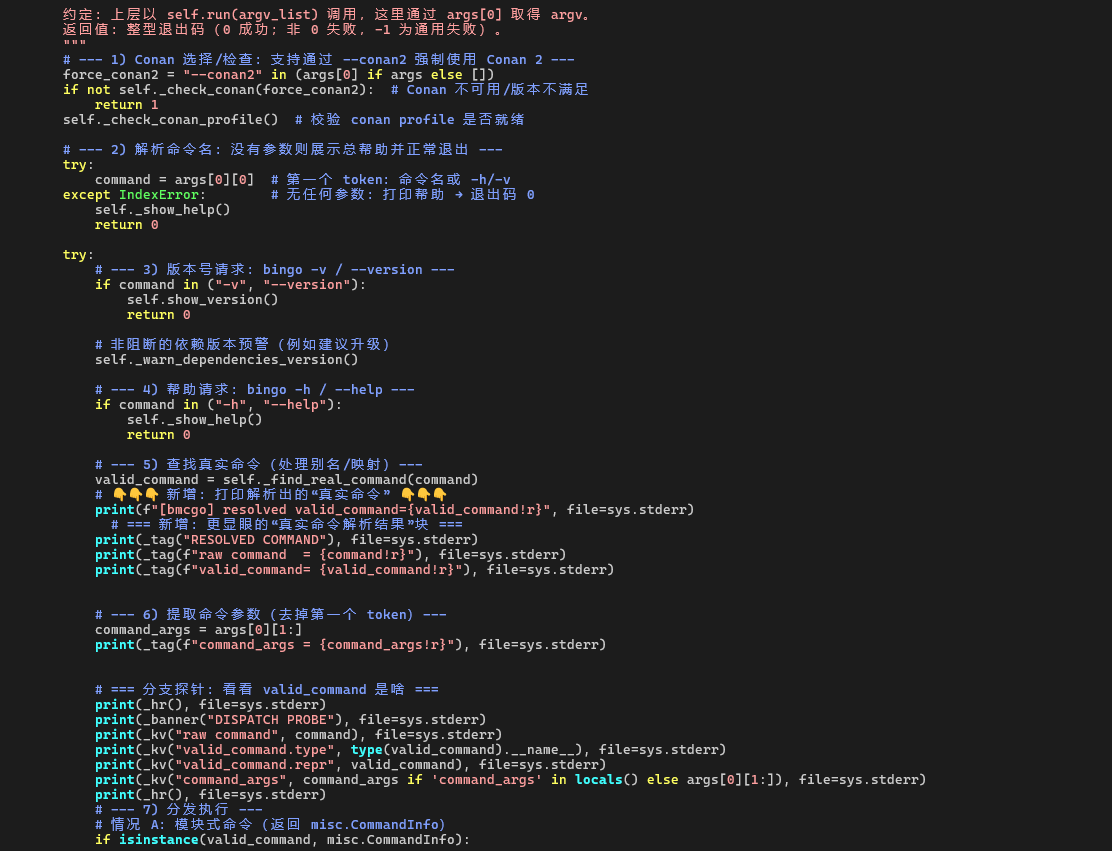
从 cli.run() 到 Command.run():命令解析与分发
上一节里,我们看到 cli.run() 最终会调用:
error = command.run(args)
接下来,通过 tags/fzf 在同一个 bmcgo/cli/cli.py 文件里搜索 def run(self, *args):,就能跳转到 Command.run。这就是 bingo 命令的真正“分发中心”。
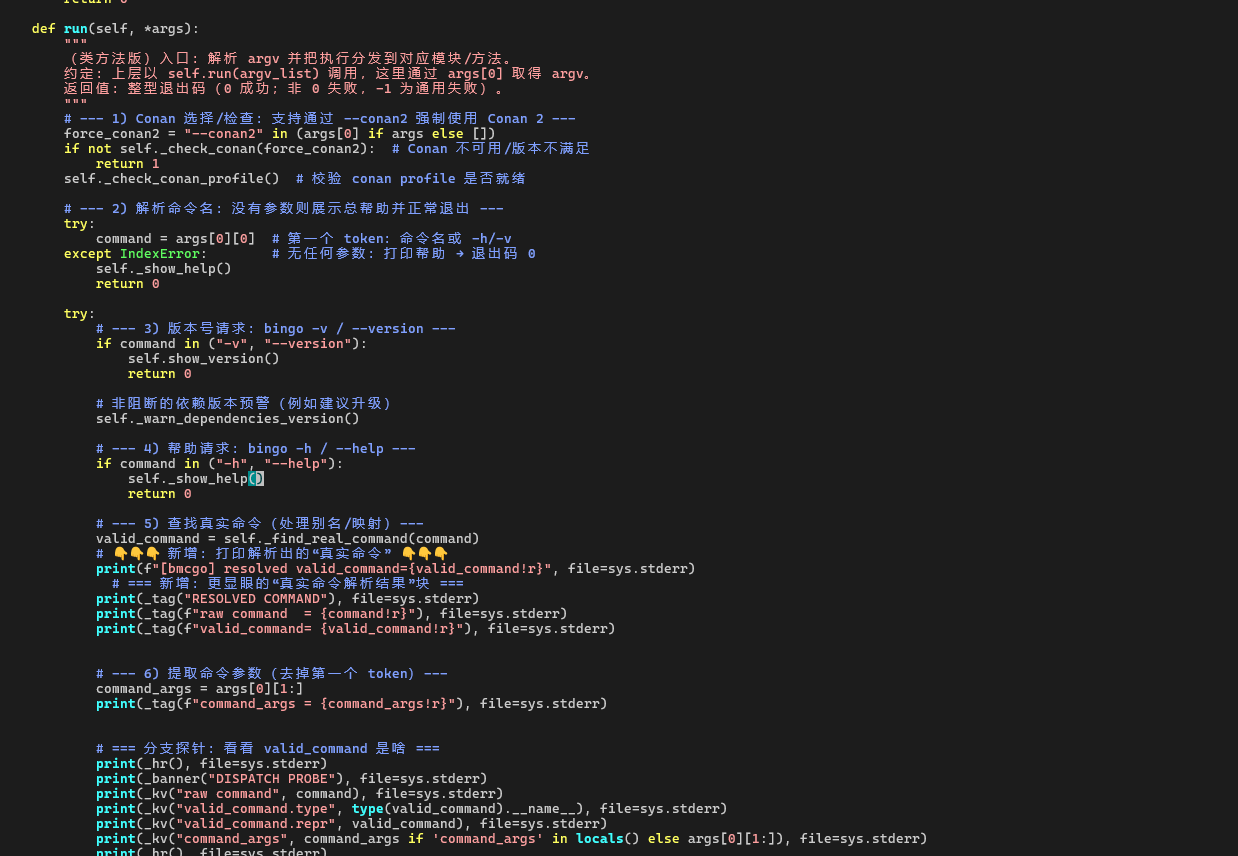
Command.run 的职责可以概括为三步:
-
把传入的
argv_list拆成「命令名 + 参数」; -
通过
_find_real_command()解析出“真实命令”(考虑别名、集成规则等); -
根据真实命令,选择对应的实现(模块 / 方法),并把参数传递过去执行,最后返回退出码。
为了观察这条链路,在 Command.run 中预先埋了一些日志探针。下面通过这些输出,一步步看它是如何把
bingo build -b openUBMC -bt debug
变成一次对 Command.build() 的调用的。
1. 拆分 argv:命令名与命令参数
Command.run 的调用约定是:上层传入的是一个 argv_list,例如:
['build', '-b', 'openUBMC', '-bt', 'debug']
因此,在函数内先做了一次拆分:
-
第一个 token 当作命令名:
command = 'build' -
剩余 token 当作命令参数:
command_args = ['-b', 'openUBMC', '-bt', 'debug']
从日志里可以验证这一点(见下图/下列输出):
[bmcgo] raw command = 'build'
[bmcgo] valid_command= 'build'
[bmcgo] command_args = ['-b', 'openUBMC', '-bt', 'debug']
到这里,命令行已经被整理成了「要执行 build 命令,并且带上 -b openUBMC -bt debug 这些参数」的形式。
2. _find_real_command():解析出“真实命令”
接着,Command.run 会调用:
valid_command = self._find_real_command(command)
这一层可以看成是“命令别名 / 集成规则”的统一入口:有些命令可能被映射成另外一个实现,或者经过一层规则判断之后再决定最终执行什么。
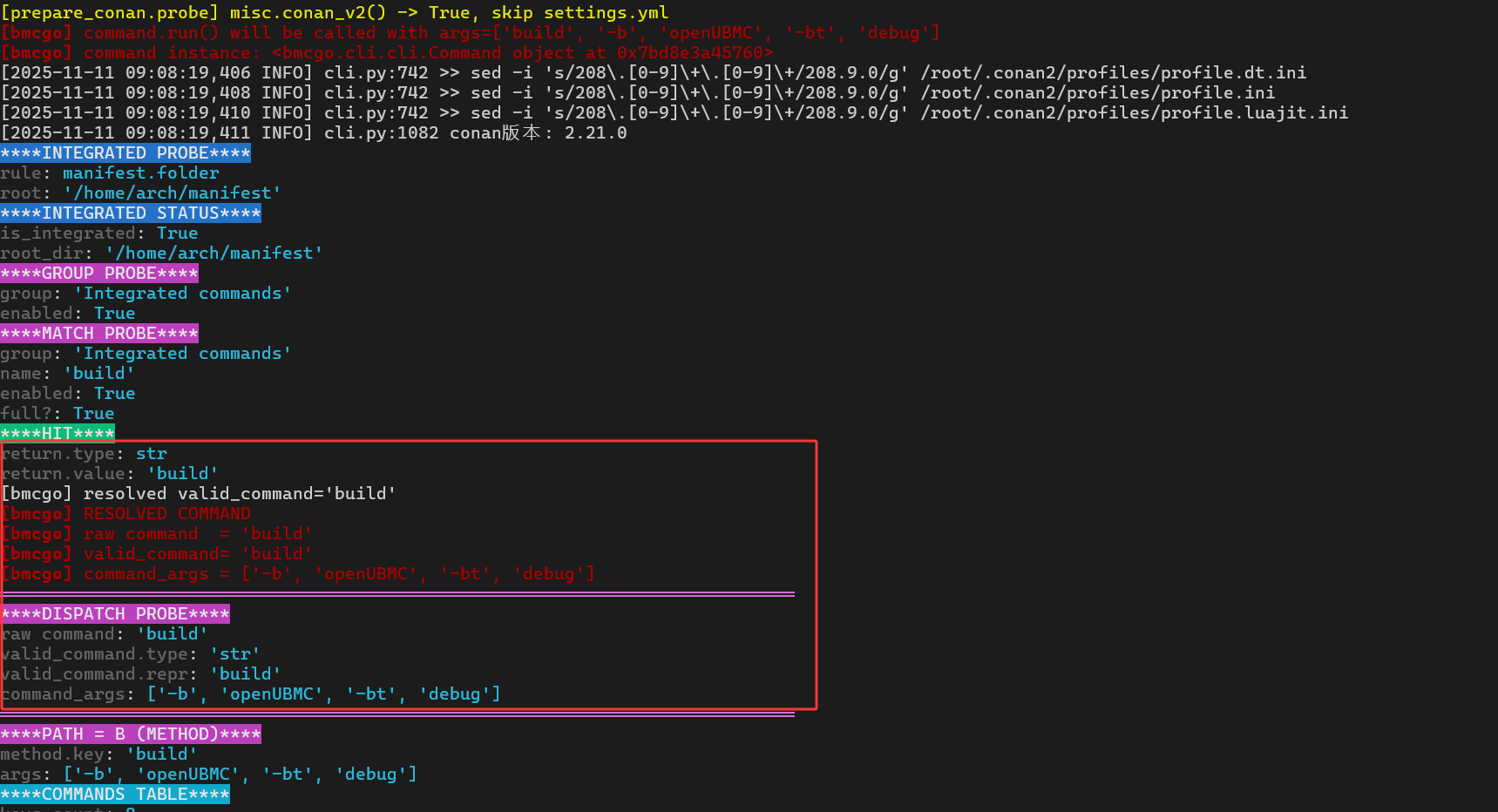
通过探针输出,可以看到本例的解析过程大致如下:
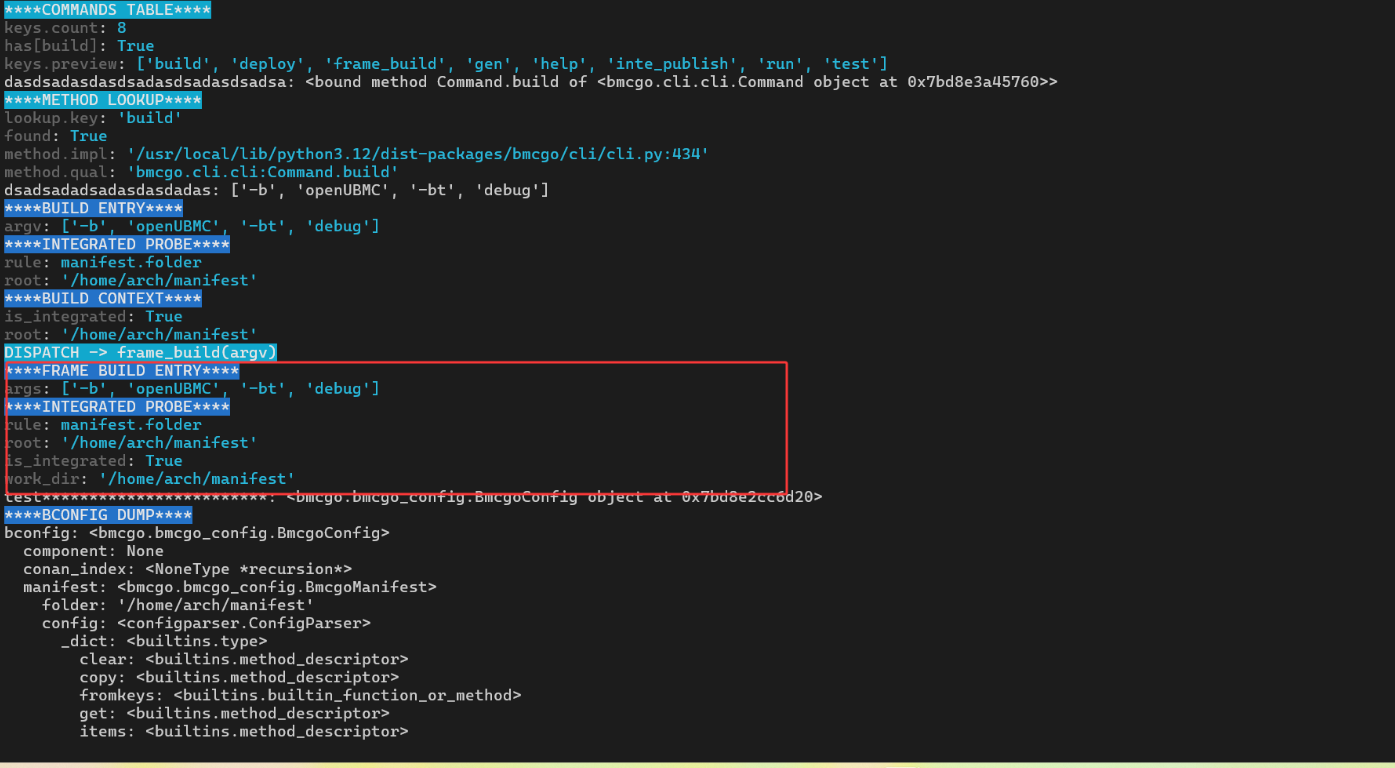
****INTEGRATED PROBE****
...
****MATCH PROBE****
group: 'Integrated commands'
name: 'build'
...
****HIT****
return.type: str
return.value: 'build'
[bmcgo] resolved valid_command='build'
[bmcgo] RESOLVED COMMAND
[bmcgo] raw command = 'build'
[bmcgo] valid_command= 'build'
[bmcgo] command_args = ['-b', 'openUBMC', '-bt', 'debug']
从这些信息可以得出两个结论:
-
_find_real_command('build')确认这是一个有效命令; -
返回的
valid_command仍然是字符串'build'(而不是某个模块描述对象)。
这一点很关键,因为后面会根据 valid_command 的类型选择不同的分发路径。
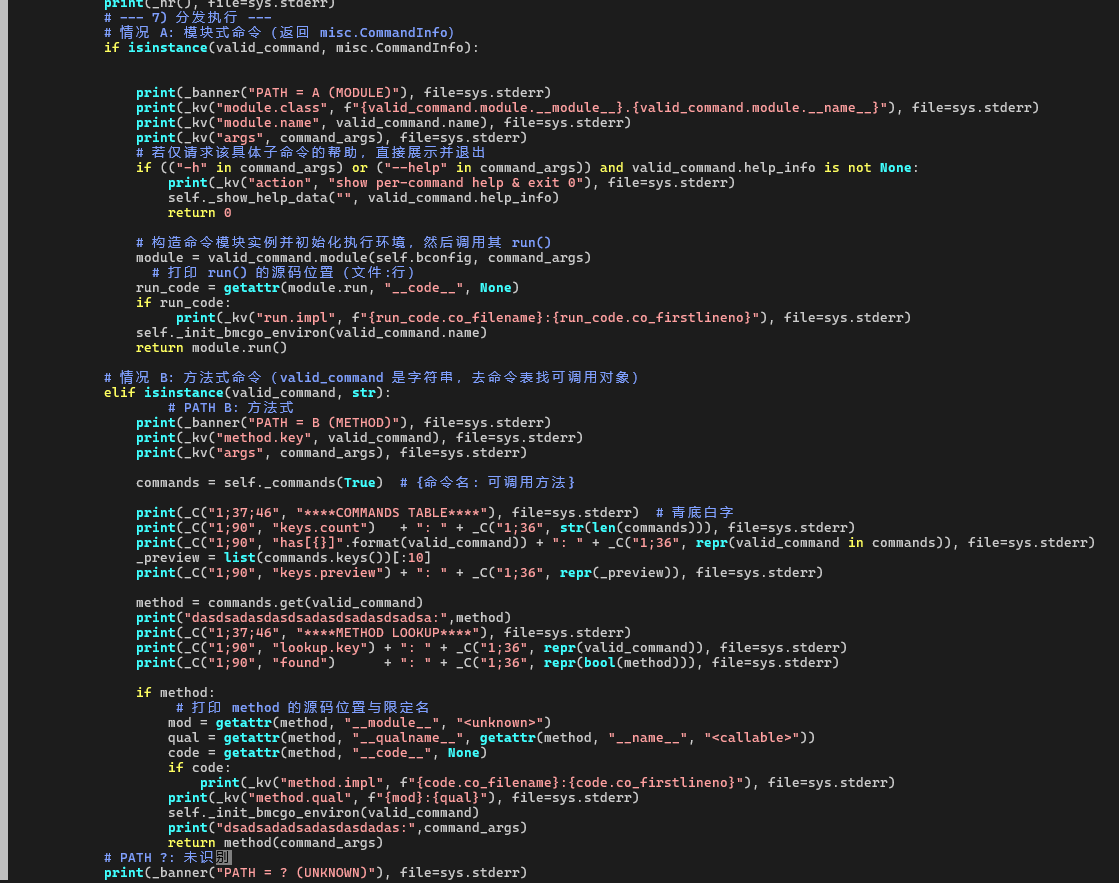
3. Path B:方法式命令,分发到 Command.build
Command.run 的分发逻辑可以简化成两条分支:
# A:模块式命令(valid_command 是 CommandInfo)
if isinstance(valid_command, misc.CommandInfo):
...
# B:方法式命令(valid_command 是 str)
elif isinstance(valid_command, str):
...
在这次 build 的例子中,valid_command 是字符串 'build',因此进入的是 Path B(方法式命令)。日志输出中也给出了非常直观的提示:
****DISPATCH PROBE****
raw command: 'build'
valid_command.type: 'str'
valid_command.repr: 'build'
command_args: ['-b', 'openUBMC', '-bt', 'debug']
════════════════════════════════════════════════════════════════════════════
****PATH = B (METHOD)****
method.key: 'build'
args: ['-b', 'openUBMC', '-bt', 'debug']
****COMMANDS TABLE****
keys.count: 8
has[build]: True
keys.preview: ['build', 'deploy', 'frame_build', 'gen', 'help', 'inte_publish', 'run', 'test']
...
****METHOD LOOKUP****
lookup.key: 'build'
found: True
method.impl: '/usr/local/lib/python3.12/dist-packages/bmcgo/cli/cli.py:434'
method.qual: 'bmcgo.cli.cli:Command.build'
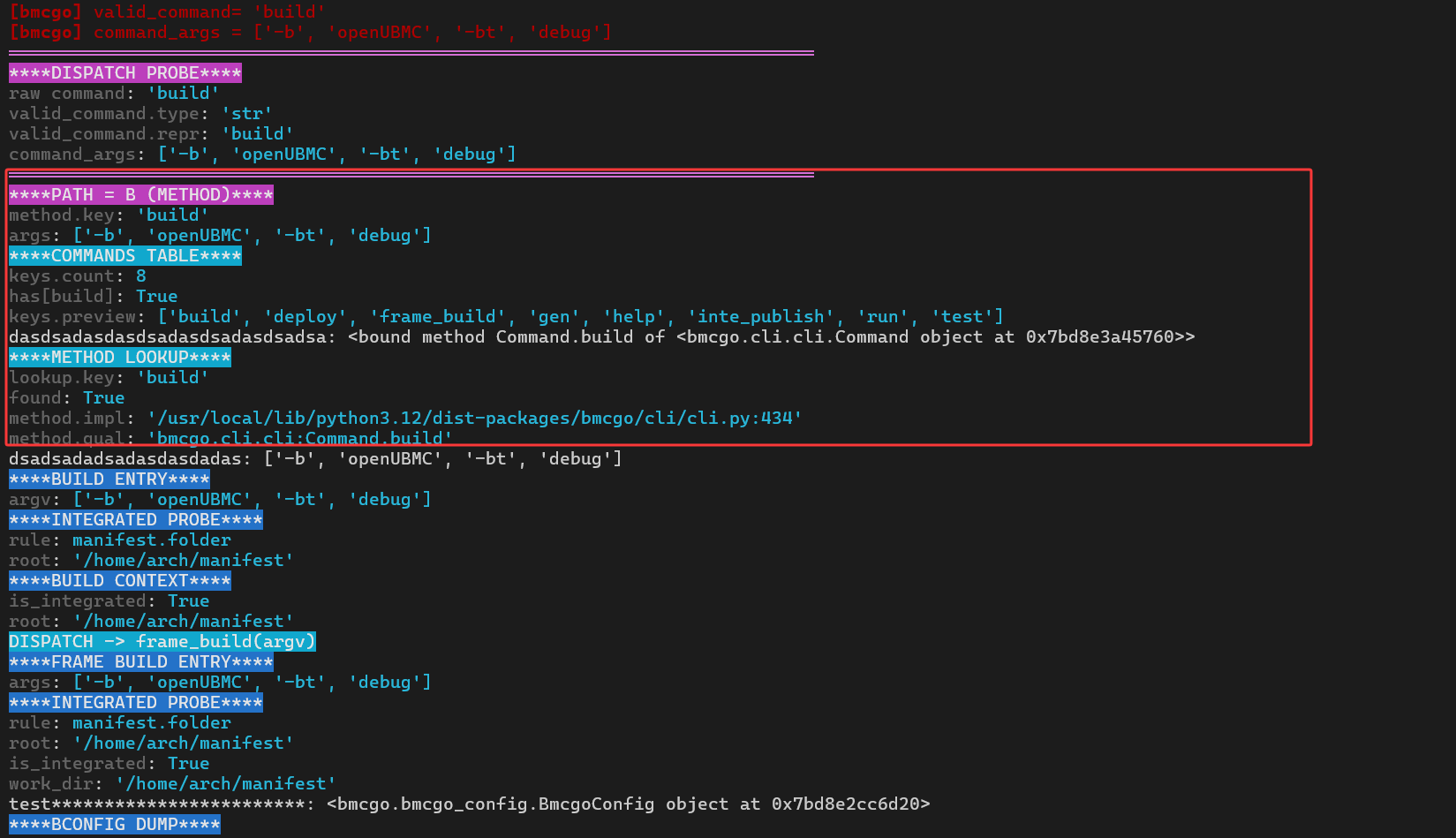
从这几段输出可以读出整个分发过程:
-
Command.run先调用self._commands(True)拿到一张“命令表”,里面是类似{ 'build': Command.build, 'deploy': Command.deploy, ... }的映射; -
然后以
valid_command作为 key 去这张表里查找:-
has[build]: True表示命令表中确实存在build; -
method.impl和method.qual标明了最终命中的实现位于cli.py:434,函数全名为Command.build;
-
-
最终,
Command.run会执行:return method(command_args)对于本例来说,可以理解成:
return self.build(['-b', 'openUBMC', '-bt', 'debug'])
至此,命令分发链路就从“命令行参数”自然收敛到了具体方法 Command.build():
bingo build -b openUBMC -bt debug
→ Command.run(['build', '-b', 'openUBMC', '-bt', 'debug'])
→ Command.build(['-b', 'openUBMC', '-bt', 'debug'])
4. 小结:这一节需要记住什么?
-
Command.run是 CLI 层的“中央路由器”,负责把argv拆成命令名和参数; -
_find_real_command()会根据规则解析出真实命令,返回值的类型决定是走模块式命令(Path A)还是方法式命令(Path B); -
通过观察探针输出,可以清楚看到:
-
build被解析成valid_command='build'; -
分发路径选择了 Path B;
-
最终落到
Command.build这个方法上。
-
build 子命令:从 Command.build 跳到 frame_build
前一节里,通过 Command.run() 的日志我们已经确认:
method.qual: 'bmcgo.cli.cli:Command.build'
也就是说,bingo build ... 最终会调用到 Command.build(...)。
由于终端里看到的是一个“方法指针”,没法直接从那里跳转函数定义,我们可以在编辑器里这样操作:
-
在
bmcgo/cli/cli.py中搜索def build, -
或者在 tags/fzf 中搜索
Command.build, 就能定位到类Command里对应的build()方法(如左图所示)。
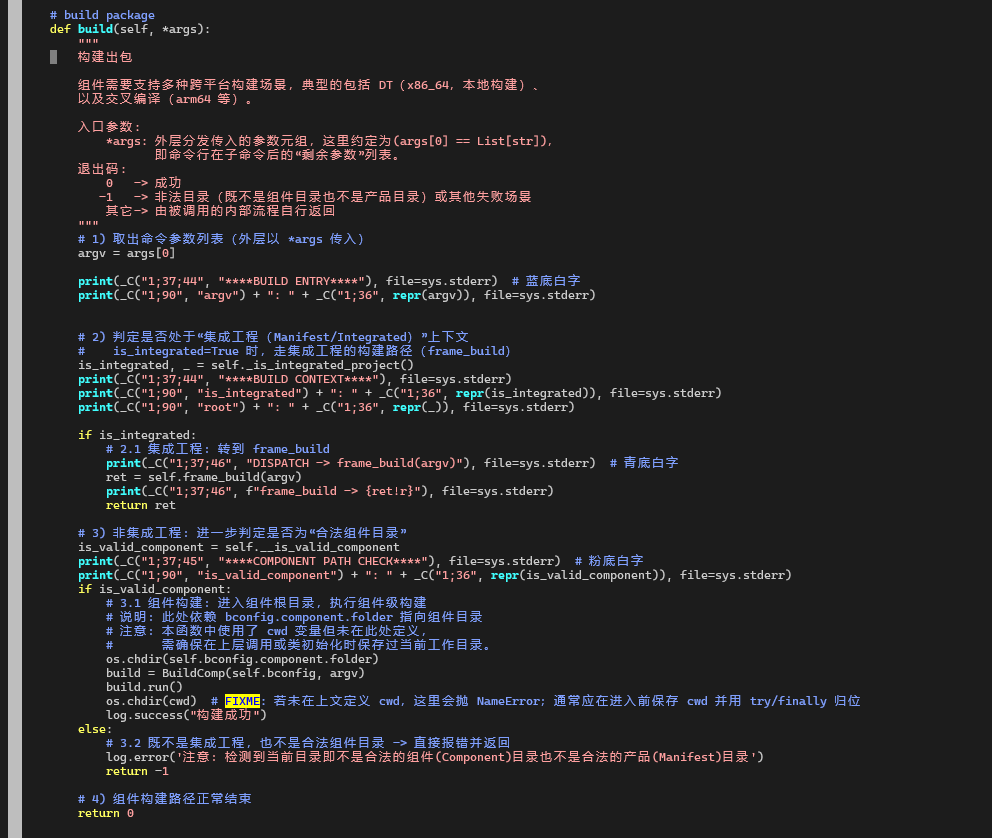
Command.build 的核心逻辑其实可以压缩成三步:
-
接收命令行参数
def build(self, *args): argv = args[0] # 例如 ['-b', 'openUBMC', '-bt', 'debug'] -
判断是否处于“集成工程(Manifest/Integrated)”场景
is_integrated, root = self._is_integrated()-
如果当前目录是一个 Manifest/集成工程,那么
is_integrated为True; -
否则就是“单组件/本地组件”的构建路径。
-
-
根据
is_integrated决定后续走向-
集成工程场景(重点) 当
is_integrated为True时,build()不直接做具体构建,而是把工作交给另一个方法:ret = self.frame_build(argv) return ret也就是说:在 Manifest 场景下,
build只是一个“门面函数”,真正负责处理集成工程构建的是frame_build()。
-
通过日志探针确认:确实进入了 frame_build
为了验证这条调用链,在 build() 和 frame_build() 里都加了一些日志探针。执行命令:
bingo build -b openUBMC -bt debug
可以看到类似下面这样的一段输出:
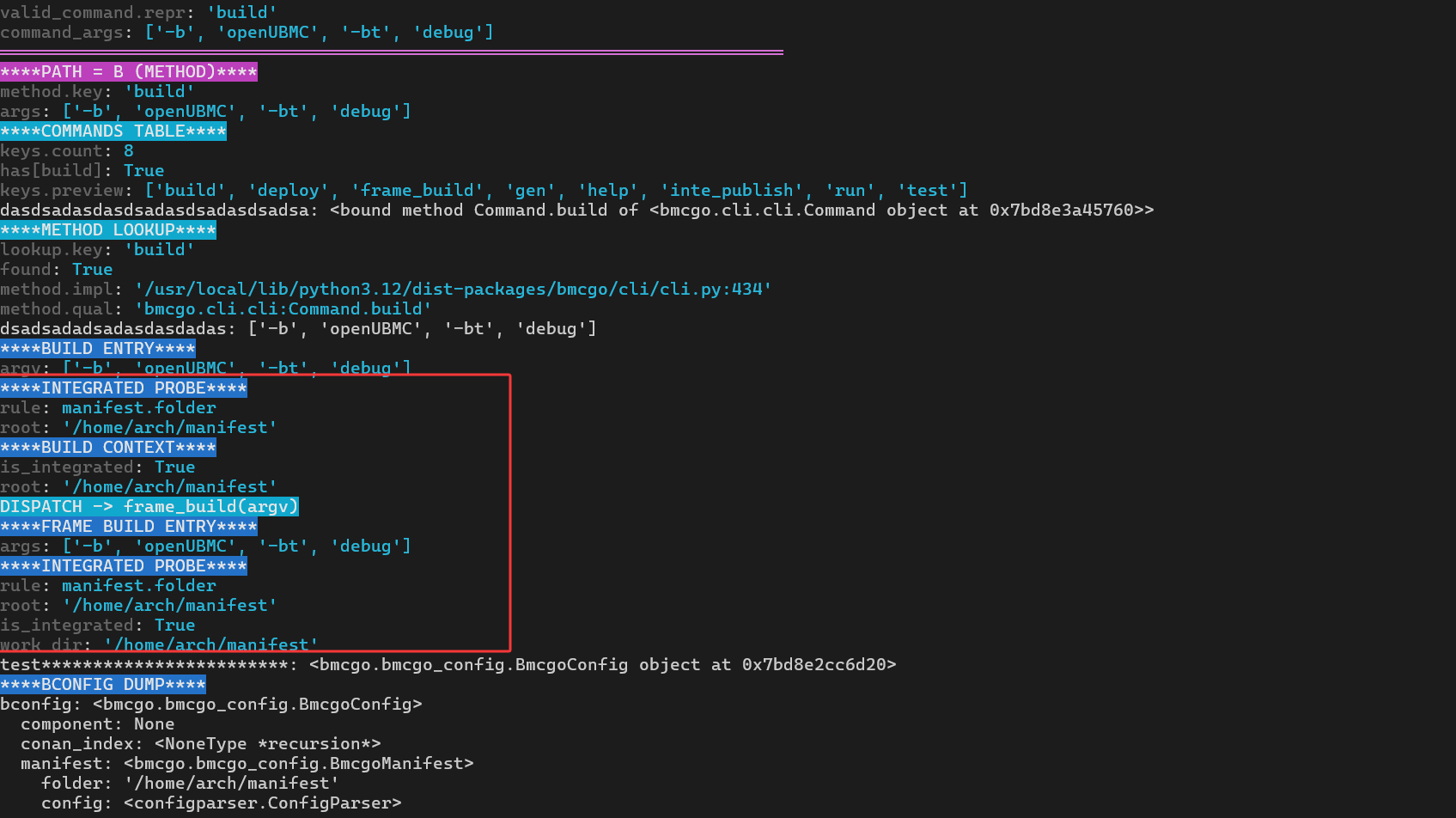
从这几行就可以很直观地确认两点:
-
build()收到了和命令行一致的参数['-b', 'openUBMC', '-bt', 'debug']; -
由于当前路径被识别为 Manifest 工程(
is_integrated: True),build()选择了DISPATCH -> frame_build(argv),而后面的****FRAME BUILD ENTRY****则说明程序已经进入frame_build()。
换句话说,在集成工程场景下,这条调用链可以概括为:
bingo build -b openUBMC -bt debug→Command.run(...)→Command.build(['-b', 'openUBMC', '-bt', 'debug'])→Command.frame_build(['-b', 'openUBMC', '-bt', 'debug'])
下一步:跳转到 frame_build
既然日志已经证明构建流程在 Manifest 场景下会落到 frame_build(),下一步就可以在 cli.py 中继续搜索:
def frame_build(self, *args):
用代码跳转功能进入这个方法,从这里开始就能看到:
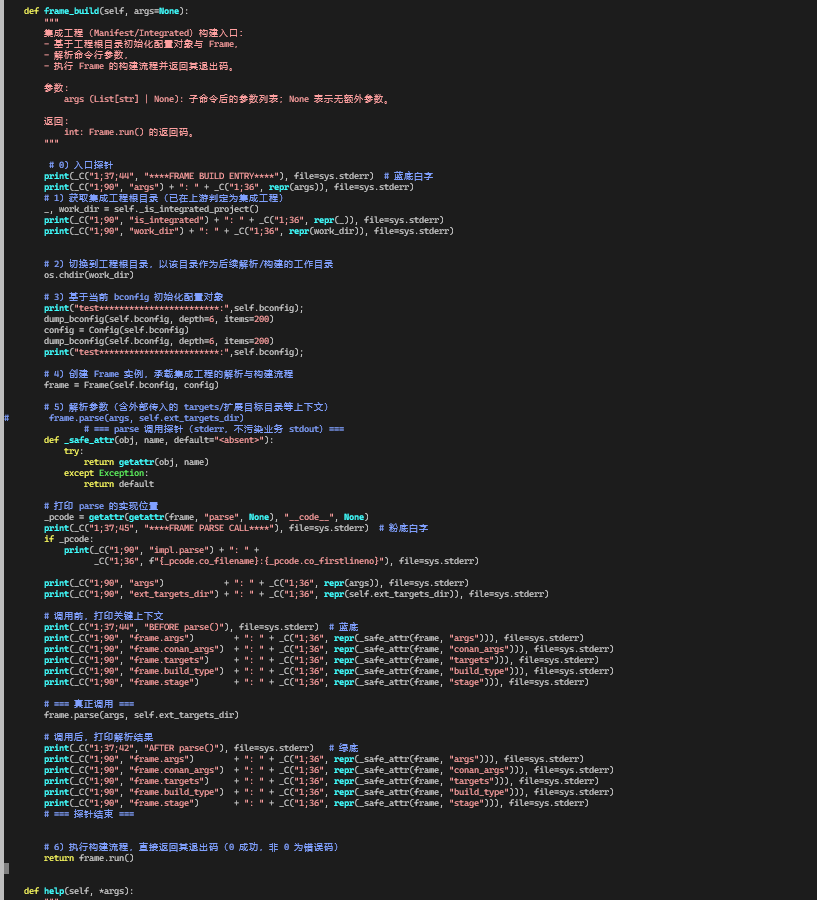
frame_build:把集成工程交给 Frame 处理
在上一节里,Command.build 在 集成工程(Manifest) 场景下会调用:
ret = self.frame_build(argv)
return ret
继续在 cli.py 里搜索 def frame_build,可以看到截图中的实现(抽最关键几行):
def frame_build(self, args=None):
# 0) 入参处理
argv = args or []
# 1) 再次确认当前是集成工程,记录 root / work_dir 等
is_integrated, root = self._is_integrated()
os.chdir(root)
# 3) 基于当前 bconfig 初始化配置对象
config = Config(self.bconfig)
# 这里有大量 dump_bconfig 的打印,我们在教程里可以略过
# 4) 创建 Frame 实例,用来承载构建配置与状态
frame = Frame(self.bconfig, config)
# 5) 解析命令行与 targets(会落在 frame.parse 里)
frame.parse(args, self.ext_targets_dir)
# 6) 执行构建流程,直接返回其退出码(0 成功,非 0 为错误码)
return frame.run()
这个函数的作用,可以用一句话概括:
在 Manifest 场景下,
frame_build负责把当前工程上下文和配置封装成一个Frame对象,然后交给Frame.parse()+Frame.run()来完成真正的构建。
用日志输出确认:已经从 build → frame_build → Frame 了
这次的探针输出,大致是这样一个结构:
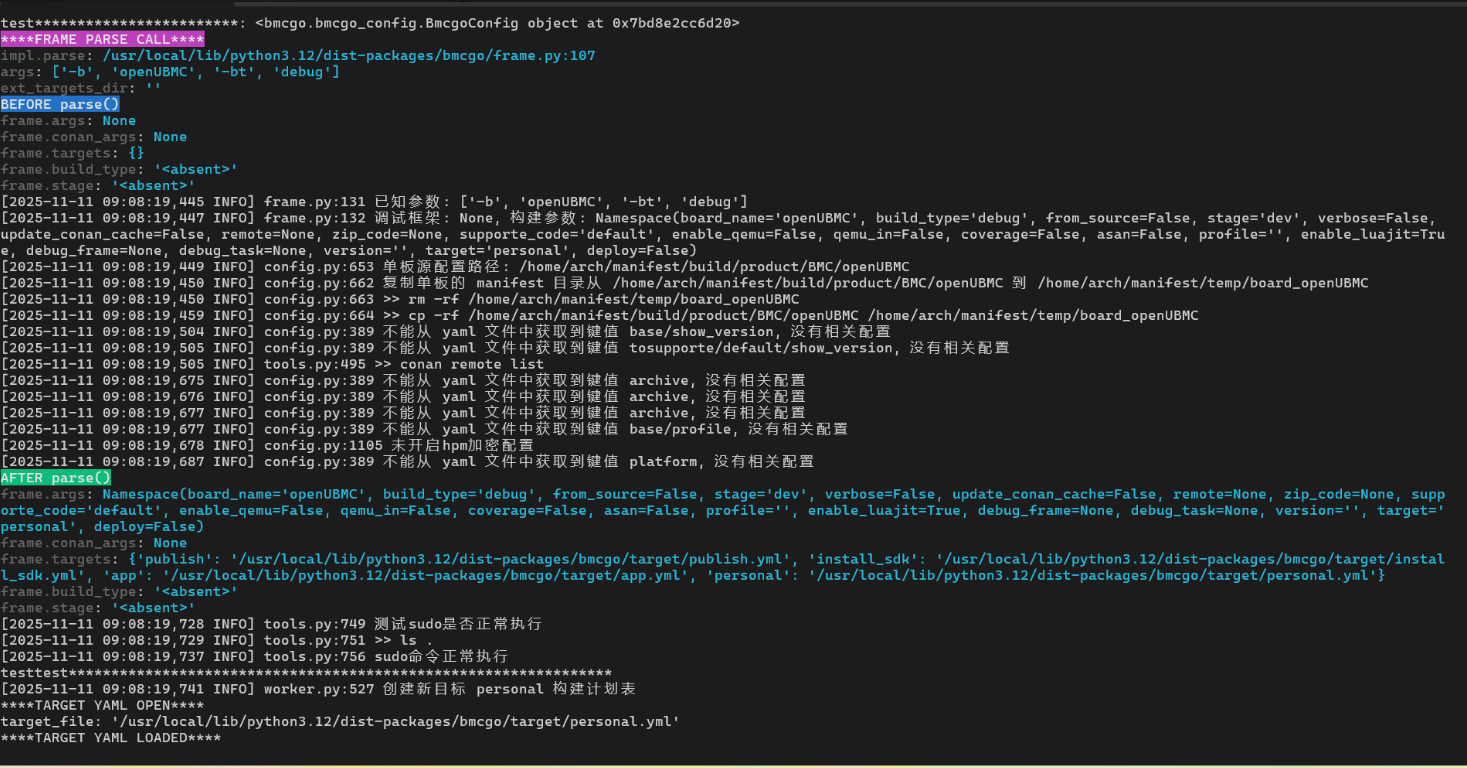
从这些日志可以看到几个关键事实:
-
build()确实把参数原样传给了frame_build(argv); -
frame_build又把相同的参数交给了Frame.parse(...)做解析; -
impl.parse: ...frame.py:107给出了Frame.parse的源码位置; -
在
parse()打完 BEFORE/AFTER 的日志之后,就会回到frame_build,继续执行return frame.run()。
也就是说,「集成工程构建」这条路径现在已经变成:
bingo build -b openUBMC -bt debug → Command.build(...) → Command.frame_build(...) → Frame.parse(...) → Frame.run()
下一步:用代码跳转进入 Frame.run
到这里,已经知道:
-
frame_build是 “集成工程的桥接函数”; -
真正完整的构建流程入口在
Frame.run()。
Frame.run:集成工程构建的最终入口
前面几节一路跟到这里:
bingo build -b openUBMC -bt debug → Command.run(…) → Command.build(…) → Command.frame_build(…) → Frame.parse(…) → Frame.run() ← 现在这一节
在 bmcgo/frame.py 里的 Frame.run(self),可以理解成:
“在集成工程(Frame)里,从 准备环境 → 启动状态服务 → 创建调度器执行目标 → 可选部署 的完整收尾流程。”
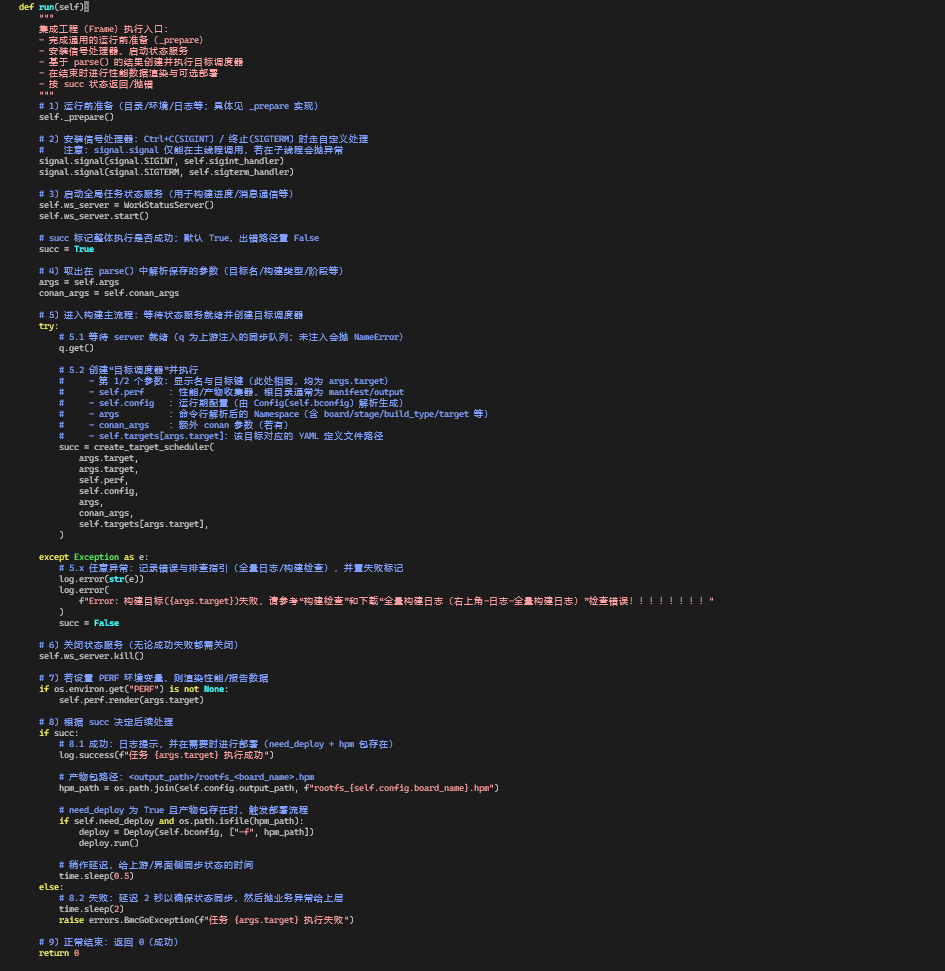
这段代码里,有几个“可以直接下结论”的关键点:
Frame.run() 是集成工程构建的最终入口: frame_build() 把 Frame 对象构造好之后,只剩这一句 frame.run()。
真正启动构建的是 create_target_scheduler(…):
传入了 args.target、self.config、self.targets[args.target] 等参数;
返回值赋给 succ,后面所有逻辑都围绕这个布尔值展开。
部署逻辑也在这里收尾:
成功时构造 rootfs_{board_name}.hpm 路径;
在 need_deploy 且文件存在的情况下,调用 Deploy(…).run()。
run 的返回值固定为 0:
正常路径下总是 return 0;
出错则抛异常,由上一层统一转换成非 0 退出码。
现在可以用一句话收束:
对于集成工程(Manifest)场景下的 bingo build -b openUBMC -bt debug,代码执行路径是:
/usr/local/bin/bingo # 命令入口脚本
→ bmcgo.bmcgo.run(...)
→ bmcgo.cli.cli.main(...)
→ bmcgo.cli.cli.run(...)
→ Command.run(argv_list)
→ Command.build(...)
→ Command.frame_build(...)
→ Frame.parse(...) # 解析 YAML + 命令行参数
→ Frame.run() # 创建 target 调度器并执行,必要时部署
其中真正“让构建发生”的,是 Frame.run() 里那次对 create_target_scheduler(…) 的调用,以及后续可选的 Deploy.run()。
1. create_target_scheduler 做的就两件事
结合源码,只说肉眼能确认的部分:
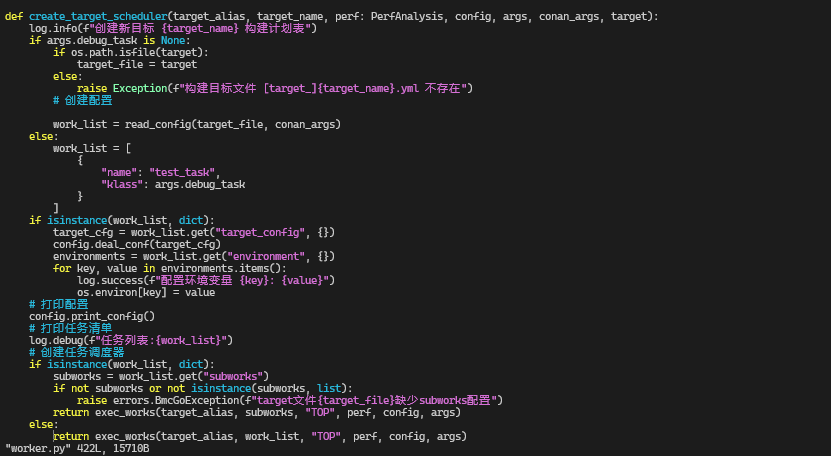
所以可以很简单地概括为:
先用
read_config把目标 YAML(例如personal.yml)读成work_list;如果是 dict:
用
target_config更新配置;用
environment设置环境变量;从
subworks里拿到要执行的任务树,交给exec_works;如果是 list:直接把这个列表当成任务列表丢给
exec_works。
1.1探针源代码
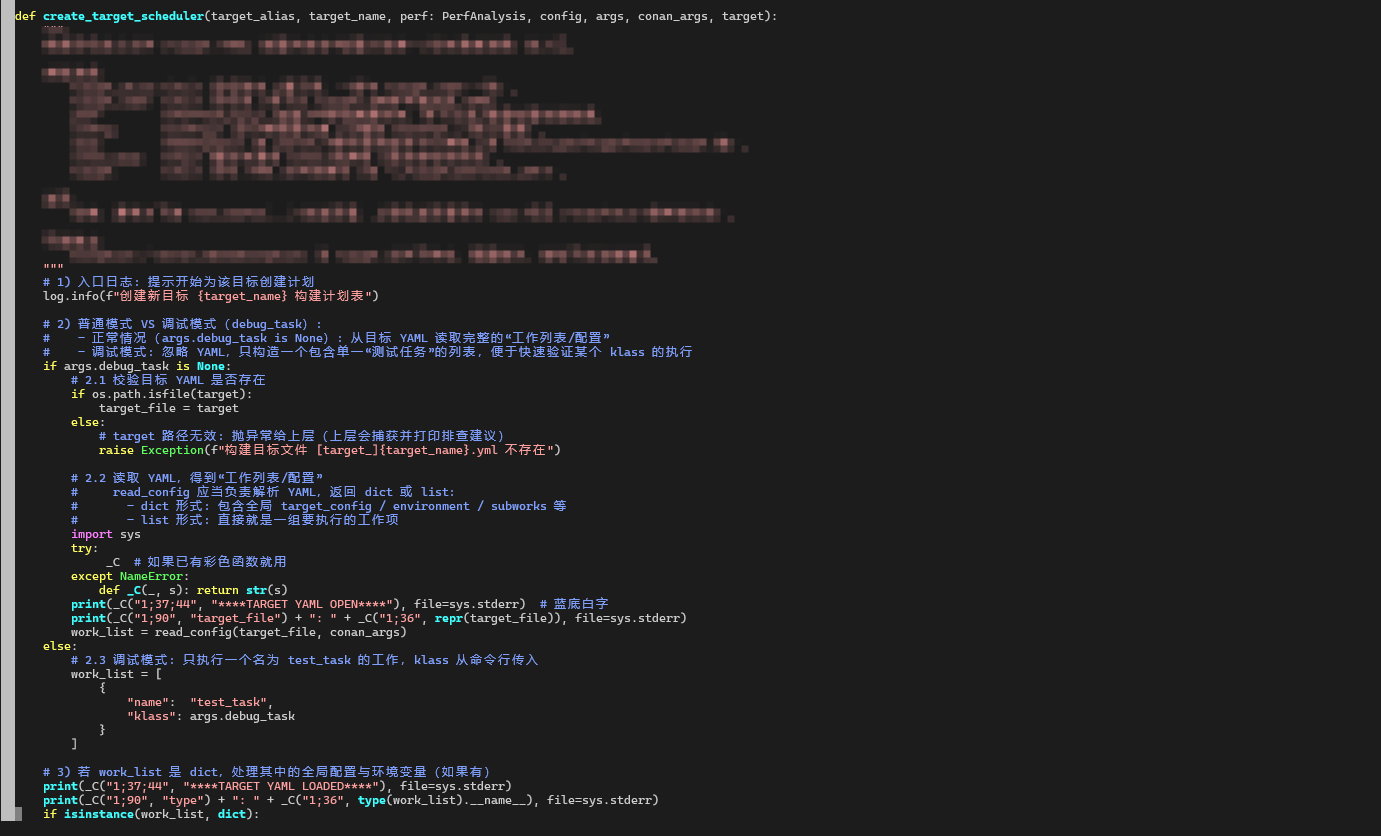

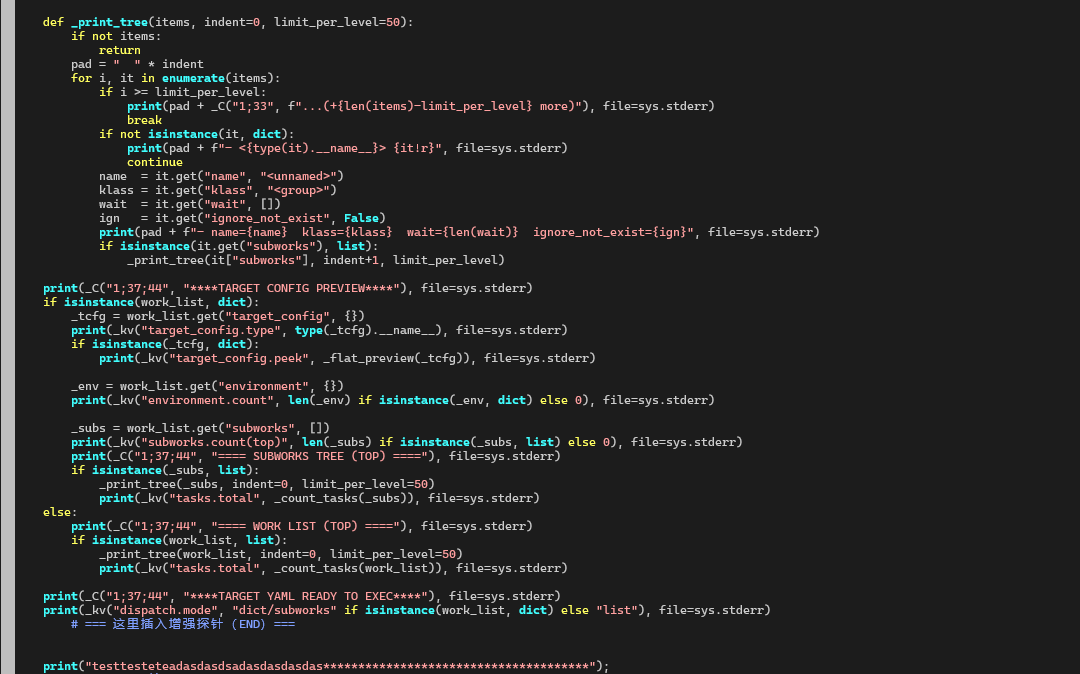
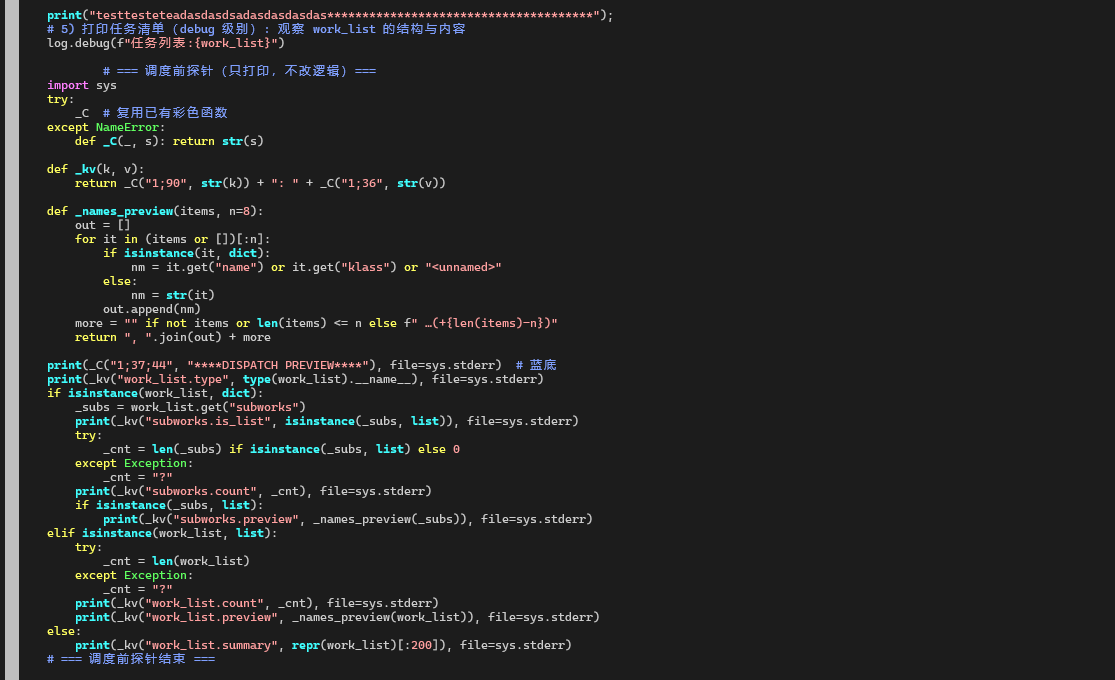

2. 探针输出证明:确实读的是 personal.yml
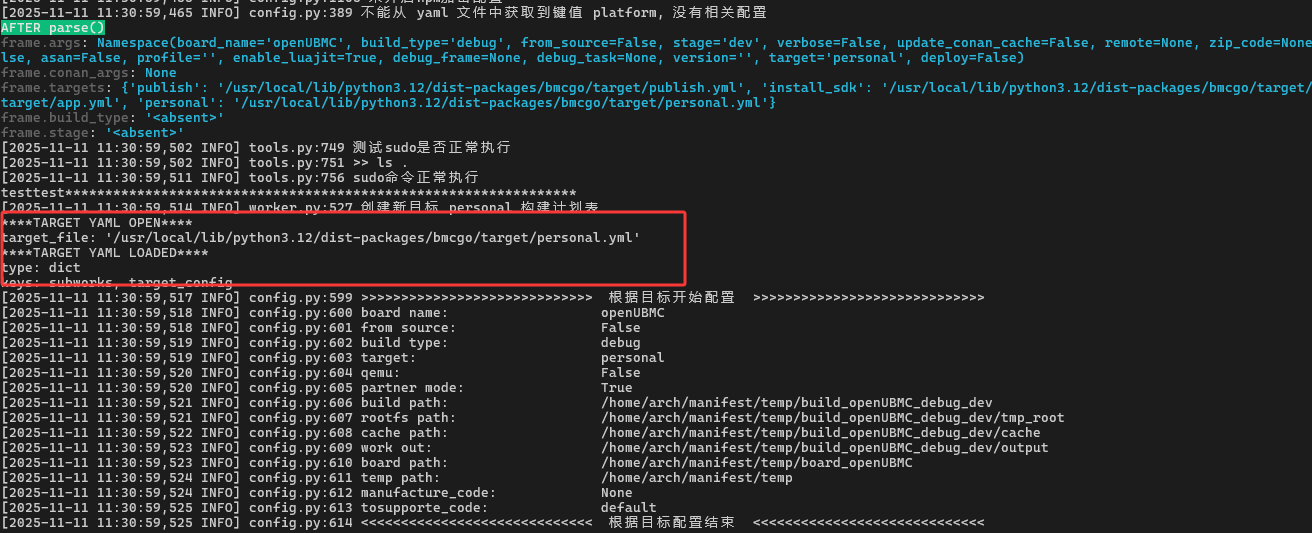
探针输出里有这一段:
****TARGET YAML OPEN****
target_file: '/usr/local/lib/python3.12/dist-packages/bmcgo/target/personal.yml'
****TARGET YAML LOADED****
type: dict
keys: subworks, target_config
这跟源码是一一对应的:
-
先打印
target_file,说明read_config读的正是personal.yml; -
type: dict+keys: subworks, target_config,说明work_list的结构就是:
work_list = {
"target_config": {...},
"subworks": [...],
# 可选: "environment": {...}
}
3. personal.yml 的结构和日志里的树是对得上的
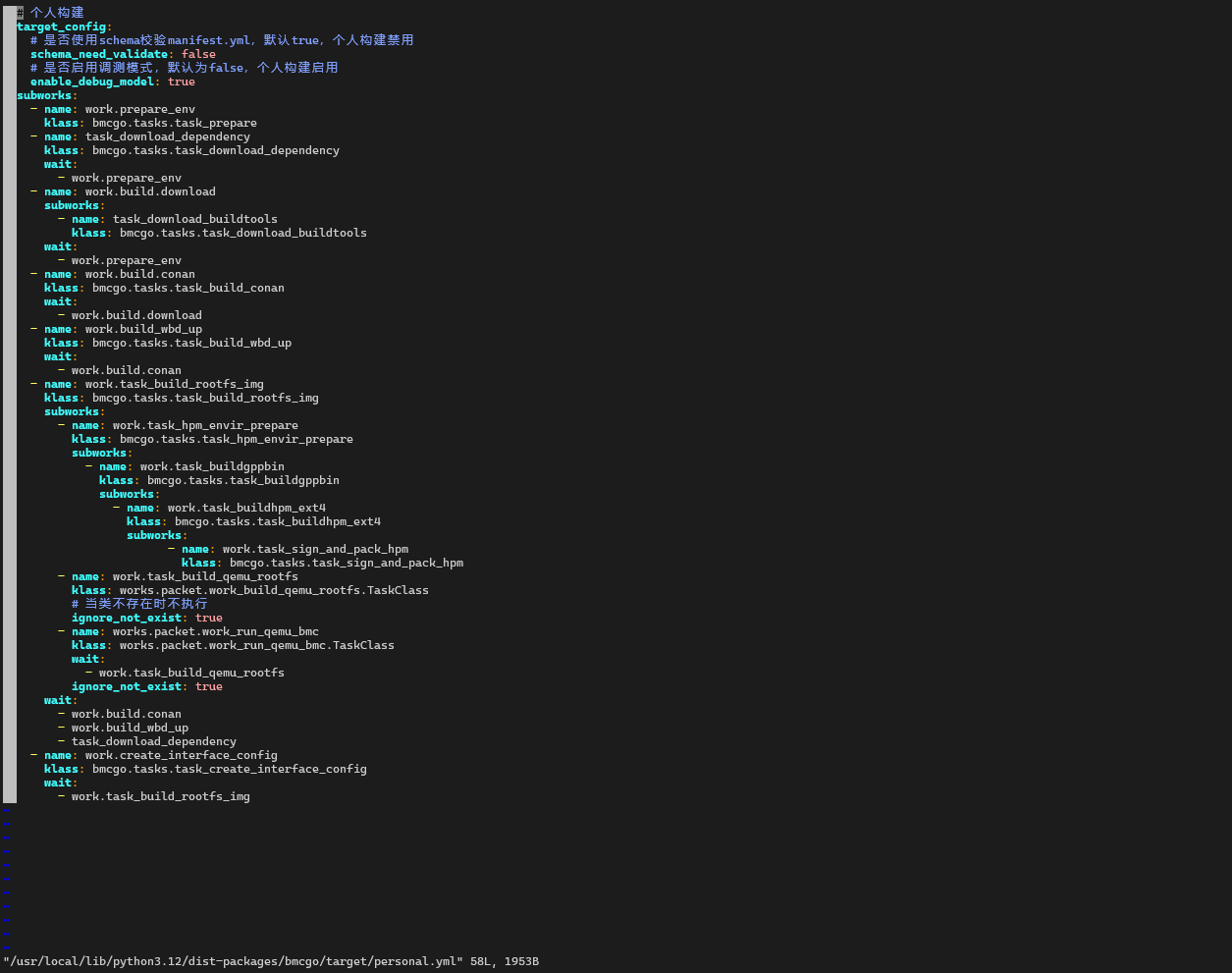
personal.yml 里顶层大概是这样:
而探针里打印的 SUBWORKS TREE 正好是同一棵树的“ASCII 形态”:
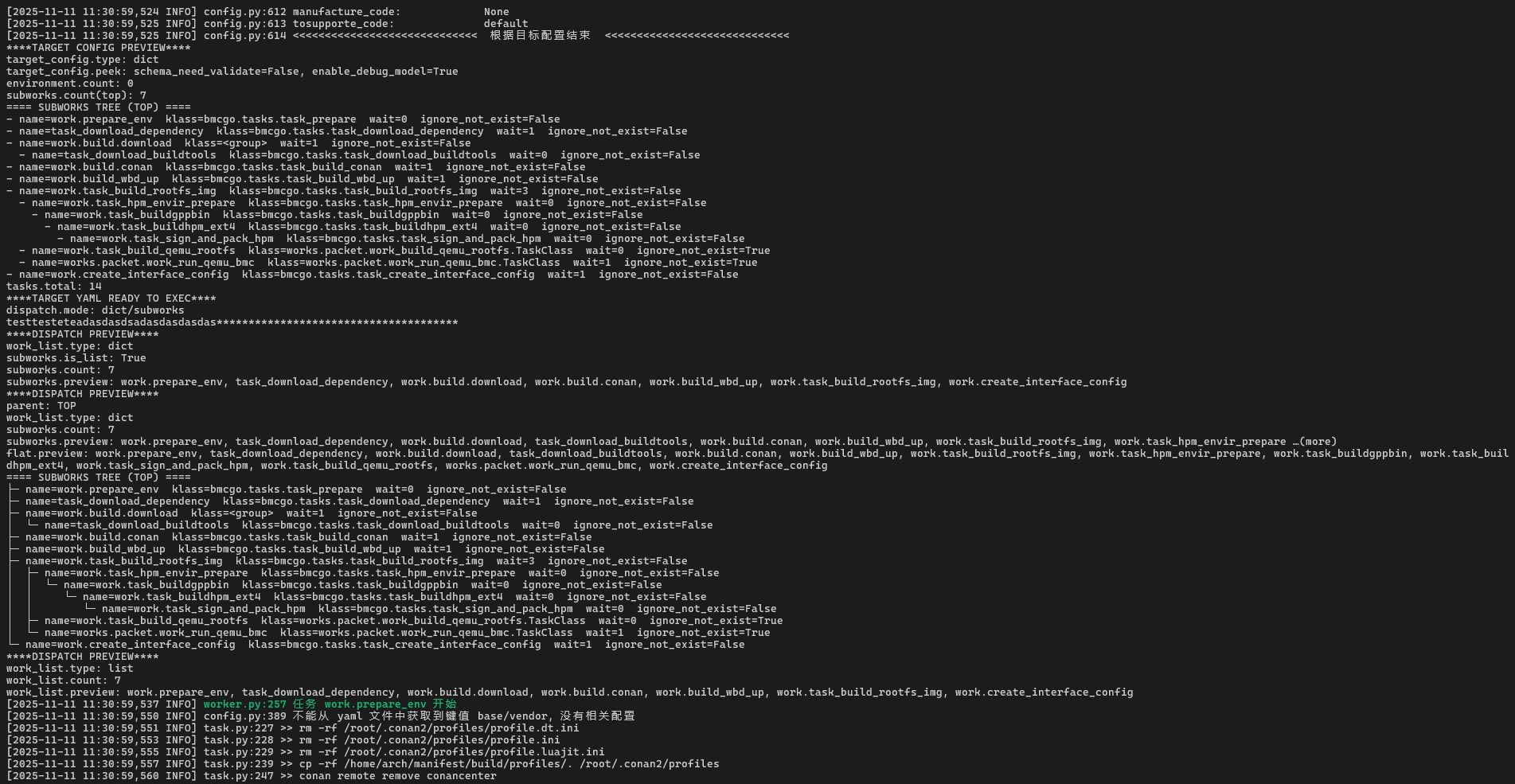
所以可以很直观地看到:
-
personal.yml 里的每一个
subworks节点,都会在日志树里出现一行; -
name/klass/ignore_not_exist等字段完全一致。
这里清晰地建立一个“YAML → Python 代码”的映射关系:
-
先看
personal.yml里某个节点的klass,比如:klass: bmcgo.tasks.task_build_rootfs_img -
在编辑器里搜索这个模块路径,跳到对应的 Python 文件:
-
搜索
bmcgo.tasks.task_build_rootfs_img -
打开
bmcgo/tasks/task_build_rootfs_img.py -
再在文件里找
class TaskClass(Task):或对应的run()。
-
-
日志的 SUBWORKS TREE 可以充当“运行时确认”:
-
如果树里能看到
work.task_build_rootfs_img这一行,说明这一步确实在执行计划里; -
如果配合后续 exec_works 的探针,还能看到具体执行顺序。——待研究
-
一句话总结:
create_target_scheduler把personal.yml解析成一个任务树(subworks), 然后交给exec_works("TOP", ...)去一个个执行。 想看某一步到底做了什么,就去找它的klass指向的 Python 模块。