环境信息
- OpenUBMC2509
问题描述
一台测试环境,出现了不限于 BIOS 丝印生成失败、SMBIOS 文件上报失败、精细化告警不记录、BIOS 无法升级等奇奇怪怪的情况
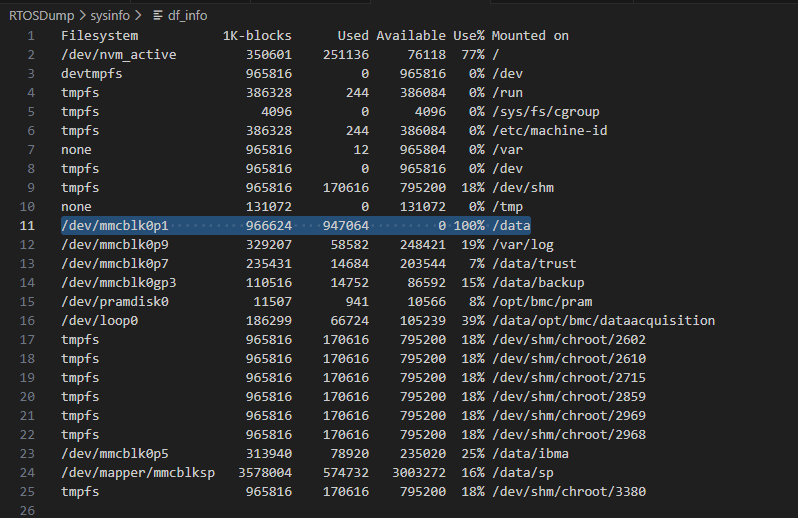
经定位发现,/data 分区占用率达到 100% ,大量 BMC 功能无法正常运行
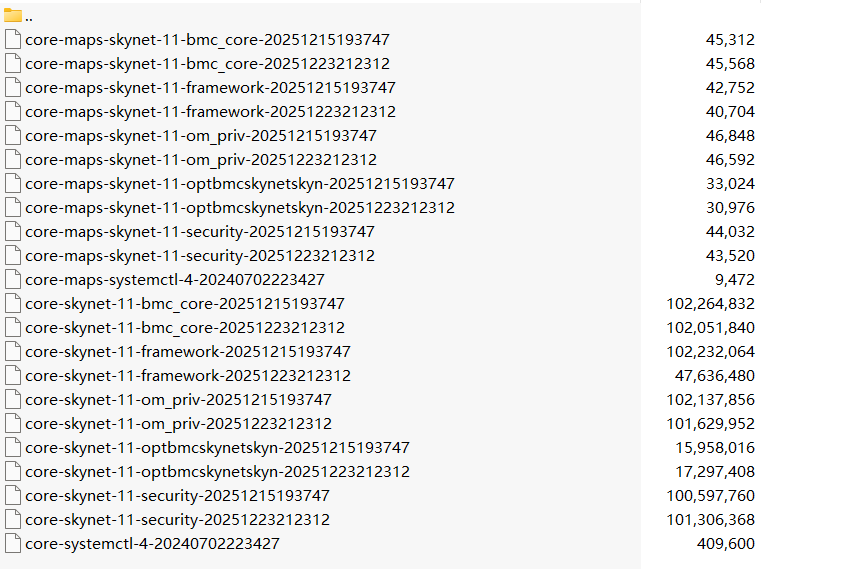
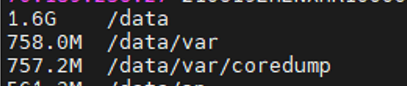
环境上有去年年中开始累计的数十个 coredump,占用了大约 750MB 的 /data 分区空间
问题:
1、coredump 没有自动清理机制吗?
2、现网包是否会生成 coredump?这个问题在现网是否会有风险?
一台测试环境,出现了不限于 BIOS 丝印生成失败、SMBIOS 文件上报失败、精细化告警不记录、BIOS 无法升级等奇奇怪怪的情况
经定位发现,/data 分区占用率达到 100% ,大量 BMC 功能无法正常运行
环境上有去年年中开始累计的数十个 coredump,占用了大约 750MB 的 /data 分区空间
问题:
1、coredump 没有自动清理机制吗?
2、现网包是否会生成 coredump?这个问题在现网是否会有风险?
答案内容由AI生成,仅供参考:
根据您提供的环境信息与上下文数据,以下是针对您提出的两个问题的详细分析和解答。
在 openUBMC 系统中,coredump 文件默认存储在:
/data/var/coredump
这一点在文档《coredump问题定位方法介绍》中有明确说明:
“在打开coredump转储后,在转储文件夹(OPENUBMC存在在/data/var/coredump)中发现对应的coredump文件”
这些文件会持续占用 /data 分区空间,如不手动干预或通过脚本管理,将长期累积。
coredump 是程序发生严重错误(如段错误、非法内存访问)时由操作系统生成的内存快照文件,常见触发信号包括:
SIGSEGV(非法内存访问)SIGABRT(程序异常中止)SIGBUS(总线错误)SIGILL(非法指令)在 openUBMC 架构中,由于底层服务使用了 C/C++ 编写的库(例如通过 Lua 调用 C 库),一旦出现内存问题,就可能引发 coredump。
是的,会生成,原因如下:
| 原因 | 说明 |
|---|---|
| 相同内核机制 | Linux 内核的 coredump 机制在所有环境中一致,只要未显式关闭,崩溃进程就会尝试生成 core 文件 |
| 一致的运行时环境 | 即使是“现网包”,只要包含 skynet 框架、Lua/C 混合调用的服务(如 skynet 主进程调用 C 库),仍可能发生 crash |
| 已有案例支持 | 正如此次排查中发现的大量历史 coredump 文件(如 core-skynet-11-bmc_core-*),表明该现象并非仅存在于开发环境 |
示例文件名含义:
core-skynet-11-bmc_core-*:bmc_core 服务在 skynet 子进程中崩溃生成的 core 文件- 时间戳显示为 2024 年至今,表明在长期运行环境中持续产生
| 风险项 | 描述 |
|---|---|
此次 /data 分区已达 100% 使用率,直接导致 BIOS 升级失败、SMBIOS 上报异常等功能失效。coredump 单个可达 100MB 以上,数十个即可占用近 1GB 空间 |
|
当 /data 满时,日志写入失败、配置无法保存、临时文件无法创建,引发连锁故障 |
|
| 大量历史 coredump 掩盖了近期的关键故障点,增加定位难度 | |
可结合监控工具检测 /data 使用率、coredump 数量,但必须配套自动化处理策略 |
为避免此类问题在现网重复发生,建议从 机制、策略、监控 三个层面进行优化:
在服务单元文件中设置 LimitCORE,控制最大 coredump 大小:
[Service]
LimitCORE=100M # 限制单个 core 文件最大为 100MB
相关知识图谱实体
Service.LimitCORE明确定义:“限制由服务进程生成的 core dump 文件的最大大小”。
也可以全局配置:
# 在 /etc/systemd/system.conf 中
DefaultLimitCORE=100M
创建定期清理脚本(如每日执行):
#!/bin/bash
CORE_DIR="/data/var/coredump"
# 保留最近7天的 coredump
find $CORE_DIR -name "core-*" -mtime +7 -delete
find $CORE_DIR -name "core-maps-*" -mtime +7 -delete
并通过 cron 注册:
0 2 * * * /path/to/cleanup_core.sh
在运维监控系统中增加对 /data 分区的使用率监控,设定阈值:
可集成 openTelemetry、Zabbix 或 Prometheus 实现自动化告警。
在高稳定性要求的现网环境中,可选择性关闭 coredump 生成:
ulimit -c 0 # 禁止生成 core 文件
或在 /etc/security/limits.conf 中配置:
* soft core 0
* hard core 0
注意:此操作将丧失故障现场取证能力,仅建议在极端稳定性优先场景下使用。
| 问题 | 回答 |
|---|---|
| 1. coredump 是否自动清理? | /data/var/coredump |
| 2. 现网包是否生成 coredump?是否有风险? | /data 分区满,引发多种功能异常 |
| 根本原因 | 长期运行积累 + 无清理策略 + 大文件占用 |
| 解决方向 | 限制大小 + 定期清理 + 监控告警 |
rm /data/var/coredump/core-* /data/var/coredump/core-maps-*
LimitCORE 限制
如需进一步协助配置清理脚本或监控项,可参考 openUBMC 官方文档或社区论坛链接:
相关链接:
1、出于可定位性考虑,目前暂时没有提供coredump文件的清理机制
2、现网包不会产生coredump文件