点击此处查看详细分析解答
PCIe设备UCE/CE/FE事件配置方法(基于2509版openUBMC)
概述
在基于openUBMC 25.09版本的系统中,正确配置GPU卡的PCIe相关故障事件(可纠正错误CE、不可纠正错误UCE、严重故障FE)是实现硬件可靠性监控的关键。本指南将结合官方实践和实际开发经验,分析用户提供的配置方案是否合理,并给出推荐的最佳实践。
正确的事件数据源映射
根据openUBMC的设计规范与华为实际适配案例,PCIe设备的各类错误事件应通过以下方式关联:
 推荐配置方式(华为适配模式)
推荐配置方式(华为适配模式)
| 事件类型 |
事件名称 |
正确数据源 |
说明 |
| 可纠正错误 (CE) |
PCIeCard.PCIeCardCEHardFailure |
PCIeDevice_1.PredictiveFault |
使用预测性故障标志位作为CE事件触发条件 |
| 不可纠正错误 (UCE) |
PCIeCard.PCIeCardUncorrectableErr |
PCIeDevice_1.UCEByBIOS 或组合逻辑 |
来自BIOS上报的UCE状态或诊断故障组合 |
| 严重故障 (FE) |
PCIeCard.PCIeCardFatalErr |
PCIeDevice_1.DiagnosticFault |
用于标识严重硬件故障 |
 核心差异:您的原始配置直接使用
核心差异:您的原始配置直接使用CorrectableError、UncorrectableError等底层寄存器值作为事件输入,而华为推荐方案更注重系统级抽象与故障聚合逻辑,提升告警准确性。
推荐事件配置示例
 1. 配置
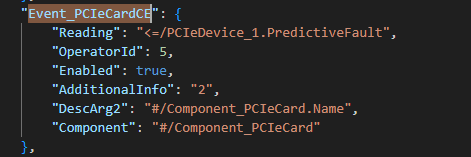
1. 配置 PCIeCardCEHardFailure 事件
"Event_PCIECardCE": {
"EventKeyId": "PCIeCard.PCIeCardCEHardFailure",
"Condition": 1,
"Reading": "<=/PCIeDevice_1.PredictiveFault",
"OperatorId": 5,
"Enabled": true,
"AdditionalInfo": "2",
"DescArg2": "#/Component_PCIeCard.Name",
"Component": "#/Component_PCIeCard"
}
说明:
- 使用
PredictiveFault 作为输入,表示设备已检测到潜在可恢复错误。
- 优于直接使用
CorrectableError 计数器,避免频繁抖动上报。
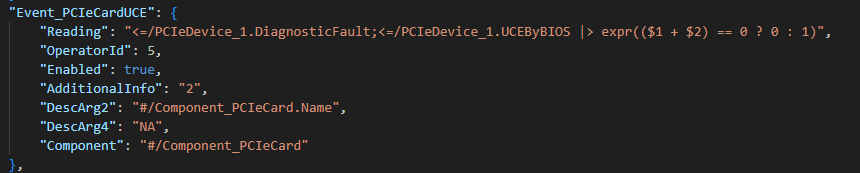
2. 配置 PCIeCardUncorrectableErr 事件
"Event_PCIECardUser": {
"EventKeyId": "PCIeCard.PCIeCardUncorrectableErr",
"Condition": 1,
"Reading": "<=/PCIeDevice_1.DiagnosticFault; <=/PCIeDevice_1.UCEByBIOS | expr(($1 + $2) == 0 ? 0 : 1)",
"OperatorId": 5,
"Enabled": true,
"AdditionalInfo": "2",
"DescArg2": "#/Component_PCIeCard.Name",
"DescArg4": "NA",
"Component": "#/Component_PCIeCard"
}
说明:
- 使用 组合逻辑表达式:当
DiagnosticFault 或 UCEByBIOS 任一为1时,触发UCE事件。
- 更全面地覆盖不可纠正错误场景,包括BIOS主动上报的情况。
3. 配置 PCIeCardFatalErr 事件
"Event_PCIeCardFE": {
"EventKeyId": "PCIeCard.PCIeCardFatalErr",
"Condition": 1,
"Reading": "<=/PCIeDevice_1.DiagnosticFault",
"OperatorId": 5,
"Enabled": "<=/Entity_GPUCard.PowerState |> expr($1 == 1 ? true : false)",
"AdditionalInfo": "2",
"DescArg2": "#/Component_PCIeCard.Name",
"DescArg4": "NA",
"Component": "#/Component_PCIeCard",
"LedFaultCode": "q$"
}
说明:
- 使用
DiagnosticFault 作为触发源,表示设备存在严重故障。
- 通过
PowerState 控制事件启用状态,仅在设备上电时生效,防止误报。
数据源设置与服务注册
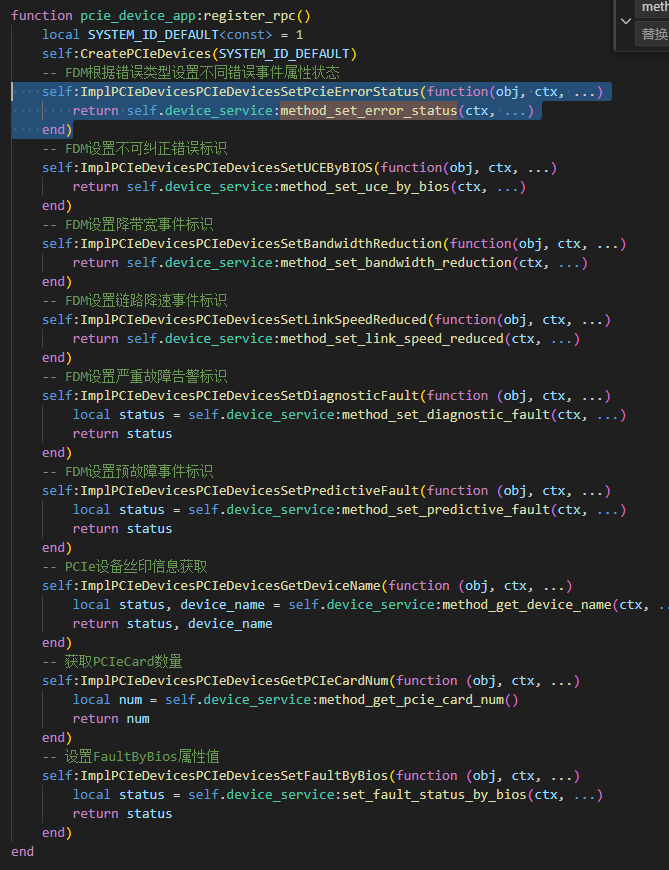
您代码中对RPC方法的注册是完全正确且符合规范的。以下是关键接口说明:
function pcie_device_app:register_rpc()
local SYSTEM_ID_DEFAULT<const> = 1
self:CreatePCIeDevices(SYSTEM_ID_DEFAULT)
-- ✅ 设置PCIe错误状态(CorrectableError/UncorrectableError/FatalError)
self:ImplPCIeDevicesPCIeDevicesSetPcieErrorStatus(function(obj, ctx, ...)
return self.device_service:method_set_error_status(ctx, ...)
end)
-- ✅ 设置BIOS上报的UCE标识
self:ImplPCIeDevicesPCIeDevicesSetUCEByBIOS(function(obj, ctx, ...)
return self.device_service:method_set_uce_by_bios(ctx, ...)
end)
-- ✅ 设置链路降速标识
self:ImplPCIeDevicesPCIeDevicesSetLinkSpeedReduced(function(obj, ctx, ...)
return self.device_service:method_set_link_speed_reduced(ctx, ...)
end)
-- ✅ 设置严重故障标识
self:ImplPCIeDevicesPCIeDevicesSetDiagnosticFault(function (obj, ctx, ...)
return self.device_service:method_set_diagnostic_fault(ctx, ...)
end)
-- ✅ 设置预故障标识
self:ImplPCIeDevicesPCIeDevicesSetPredictiveFault(function (obj, ctx, ...)
return self.device_service:method_set_predictive_fault(ctx, ...)
end)
end
总结:上述注册逻辑正确,底层驱动可通过这些接口动态更新设备状态。
建议修改点(对比您的原始配置)
| 问题项 |
您的原始配置 |
推荐修改 |
| CE事件源 |
CorrectableError |
改为 PredictiveFault |
| UCE事件源 |
UncorrectableError |
改为 DiagnosticFault + UCEByBIOS 组合 |
| 表达式语法 |
/<= → 应为 <=/ |
修正路径语法 |
| 是否需要更新event_def.json版本号? |
必须更新,否则事件不生效 |
参考文档:OpenUBMC事件开发指南 |
最佳实践建议
-
使用抽象层状态字段
- 不建议直接绑定底层寄存器(如CorrectableError计数器),因其可能频繁波动。
- 推荐使用由驱动聚合后的状态字段:
PredictiveFault、DiagnosticFault、UCEByBIOS。
-
启用组合条件判断
- 对于关键事件(如UCE),采用多个信号源“或”逻辑判断,提高可靠性。
- 示例:
(DiagnosticFault || UCEByBIOS) ? 1 : 0
-
动态启用控制
-
确保版本号更新
- 修改
event_def.json 后必须升级版本号(version字段),否则新事件不会被加载。
-
验证工具使用
总结
结论:
您当前的配置在RPC服务注册层面是正确的,但在事件定义的数据源选择上存在优化空间。
推荐做法:
- 将CE事件源改为
PredictiveFault
- 将UCE事件改为
DiagnosticFault + UCEByBIOS 的组合逻辑
- 修正表达式语法(
/<= → <=/)
- 更新
event_def.json 版本号以确保生效
该配置策略已在华为GPU/NPU卡适配中广泛验证,具备更高的稳定性与准确性,建议遵循此模式进行适配开发。