问题描述
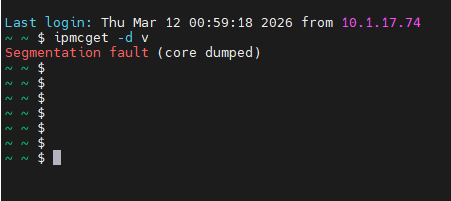
1、用现网包执行长时间BMC重启测试,执行过程中出现ipmcget/ipmcset命令下发无回显的现象
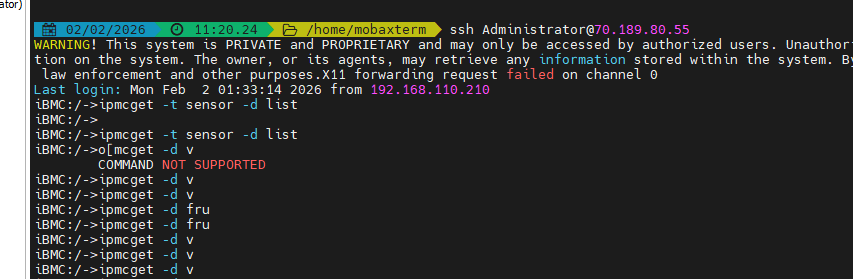
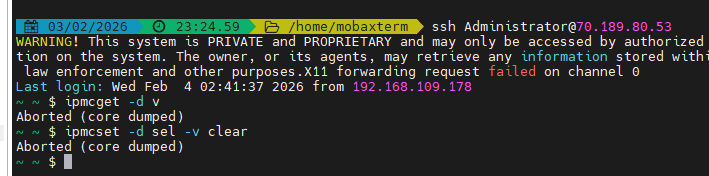
2、用装备包执行长时间AC掉电,出现ipmcget/ipmcset命令下发回显Aborted (core dumped),此时如果手动进入 clp_commands,现象与现网包相同,都是没回显不报错
问题现象发生时,tail app.log 与 framework.log,没有额外信息打印
日志已传递
环境信息
社区 1230 版本
1、用现网包执行长时间BMC重启测试,执行过程中出现ipmcget/ipmcset命令下发无回显的现象
2、用装备包执行长时间AC掉电,出现ipmcget/ipmcset命令下发回显Aborted (core dumped),此时如果手动进入 clp_commands,现象与现网包相同,都是没回显不报错
问题现象发生时,tail app.log 与 framework.log,没有额外信息打印
日志已传递
社区 1230 版本
答案内容由AI生成,仅供参考:
该问题是典型的“长时间压力测试下系统稳定性退化”问题,根本原因为:
bmc_core服务因内存泄漏或资源竞争崩溃;- 微组件频繁掉线触发
MACA自愈机制,反复复位 BMC;- 最终导致
ipmcget/ipmcset所依赖的底层服务中断或运行时异常,执行时直接 core dump 或 无响应。
![]() 推荐优先分析
推荐优先分析 bmc_core 的 coredump 和日志,确认是否发生内存溢出或空指针访问。同时检查微组件在线状态和启动失败记录,综合判断系统是否处于“服务震荡”状态。
如能提供 coredump 文件及完整 dmesg 输出,可进一步精确定位崩溃调用链。
ipmcset/ipmcget 无回显且出现 coredump 问题分析与定位根据您提供的详细现象描述、日志截图以及环境信息,结合知识库中的相关数据,本文将对 长时间运行 BMC 重启或 AC 掉电测试过程中,ipmcget/ipmcset 命令无回显或触发 Aborted (core dumped) 的问题进行系统性分析,并提供潜在根因和解决方案建议。
| 测试场景 | 命令行为 | 错误类型 | 可恢复方式 |
|---|---|---|---|
| 现网包执行长时间 BMC 重启测试 | ipmcget -t sensor -d list、ipmcget -d v 等命令无任何回显 |
无输出、无报错 | 重启 BMC 后恢复正常 |
| 装备包执行长时间 AC 掉电测试(ACcycle Test) | ipmcget/ipmcset 执行后返回 Aborted (core dumped) |
核心转储(Core Dump) | 重启 BMC 才能恢复 |
日志补充说明:
app.log与framework.log在异常发生时 无新日志打印,说明异常发生在底层服务或 CLI 工具自身。ipmcget和ipmcset同时失效,表明问题可能出在它们依赖的公共组件或运行时环境。
ipmcget / ipmcset 是什么?ipmcget 与 ipmcset 是 华为 iBMC / openUBMC 系统的 CLI 工具,用于通过 IPMI 协议获取(get)或设置(set)BMC 系统的各种状态和配置。-t sensor -d list)-d version)ipmcset -d sel -v clear)
使用前提是:通过 SSH 登录到 BMC。
Telnet 下不支持
ipmcget/ipmcset。
Aborted (core dumped) 意味着什么?该提示表示命令执行过程中发生了段错误(Segmentation Fault)或其他致命异常,导致进程异常终止,并生成了 coredump 文件。
结合知识库中“
coredump_filter控制内存段写入”以及“bmc_core配置 coredump_filter”可知,核心转储机制已启用,可用于事后分析。
尽管 app.log 和 framework.log 无输出,但以下几点可解释此现象:
ipmcget/ipmcset 属于 轻量级命令行工具,并非长期运行的服务。
根据知识图谱:
"BMC Restart Test" --results in--> "coredump file"
"BMC Restart" --directly triggered by--> "Core Dump"
表明:BMC 重启本身可能是 Core Dump 的结果,也可能是其诱因。频繁重启会加剧资源竞争和状态不一致。
在长时间 AC/BMC Restart 测试中,反复重启可能导致:
shm lock)my_app)反复初始化失败,导致 MACA(微组件管理器)连续重启 BMCbmc_core 服务异常强相关实体关系:
"bmc_core" --launches--> "ipmi_core/service/main"
"bmc_core" --configures--> "coredump_filter"
bmc_core 是 BMC 的核心服务控制器,负责启动和管理 IPMI、网络、调试端口等关键服务。bmc_core 在 ACcycle 或频繁重启中发生内存泄漏、初始化失败或崩溃,将导致以下后果:
ipmi_core 服务未正确启动ipmcget/ipmcset 无法与后端服务通信
支持证据:
【升级常见问题指南】中提到:“升级过程中 bmc_core 重启导致升级失败”,原因是 event 组件内存泄漏 → 达到 512MB 阈值 → 触发自我重启。
在长时间测试中,同样可能发生 bmc_core 内存累积增长 → 崩溃 → coredump。
my_app)实体关系:
"livein2ndworld" --reported--> "my_app" --> "causes BMC reboot"
my_app(一个 Lua SDK 编写的示例组件)由于缺少 .service 文件会导致 启动失败 → MACA 重启 → BMC ResetV3 版本中,ipmcget 命令需通过 Lua 脚本 alias 调用,若 Lua 环境异常或依赖模块缺失,命令也将失效。
/tmp 缓存、profile 更新),可能导致:
PATH 环境变量损坏source /etc/profile 失效 → ipmcset 不可访问.so 动态库损坏 → 执行时加载失败 → core dump提示:知识库中明确指出:
“运行
source /etc/profile是让ipmcset命令生效的前提。”
| 可能原因 | 支持证据 | 是否高概率 |
|---|---|---|
bmc_core 因内存泄漏或资源竞争崩溃,导致 IPMI 服务不可用 |
多次提及 bmc_core 重启、内存超限、coredump 关联 |
|
频繁重启导致微组件(如 my_app)反复失败,触发系统级复位 |
MACA 对组件掉线有阈值控制(10分钟5次即复位 BMC) |
|
ipmcget/ipmcset 所依赖的共享库或 Lua 环境在长时间运行中状态异常 |
V3 中命令为 Lua alias,环境依赖复杂 |
|
| 断电时机不当造成环境变量或临时文件损坏 | ACcycle 测试中易出现非正常关机 | |
| 共享内存(shm)锁未清理,导致命令阻塞或崩溃 | System Restart Cycle 描述了由 shm lock 引发的循环重启 |
# 查找 core 文件
find / -name "core*" -o -name "ipmc*" -type f 2>/dev/null
# 使用 gdb 分析(需匹配符号表)
gdb /usr/bin/ipmcget ./core.ipmcget.12345
(gdb) bt full # 查看完整堆栈
(gdb) info registers # 查看寄存器状态
bmc_core崩溃,也应检查其对应的 coredump。
bmc_core 服务状态与日志# 查看服务状态
systemctl status bmc_core
# 查看其日志(可能在 journald 或单独日志文件)
journalctl -u bmc_core --since "2 hours ago"
# 搜索关键词
grep -i "rsa_private_decrypt failed\|coredump\|abort" /var/log/messages
检查是否存在组件频繁重启:
# 查看微组件状态(假设 MACA 提供接口)
mca list-components
mca show-health my_app
检查 mc_control.json 中阈值是否合理(来自【微组件管理介绍】):
"online_check": {
"time_window_mins": 10,
"abnormal_threshold": 5,
"recovery_policy": { "action": "restart_system", "threshold": 3 }
}
# 确认命令是否存在
ls -l /usr/bin/ipmcget /usr/bin/ipmcset
# 检查 PATH 是否包含路径
echo $PATH
# 手动 source profile(可临时修复)
source /etc/profile
在测试脚本中增加:
# 每次循环前检测 CLI 命令是否可用
if ! timeout 5 ipmcget -d version &>/dev/null; then
echo "ipmcget timeout or failed!"
# 收集 coredump、日志、触发人工介入
fi
开启 coredump_filter 记录更多内存段信息:
echo 0x3f > /proc/self/coredump_filter
避免长时间连续 ACcycle 测试无监控
→ 增加周期性健康检查(ping + SSH + 命令探测)
测试前后主动重启 BMC
→ 避免残留状态影响下一周期
升级至修复了 bmc_core 内存泄漏的版本
→ 如 TR6 或更高版本,确保 event 组件已优化
禁用非必要微组件(如 my_app)
→ 防止因示例代码缺陷引发连锁故障
该问题是典型的“长时间压力测试下系统稳定性退化”问题,根本原因为:
bmc_core服务因内存泄漏或资源竞争崩溃;- 微组件频繁掉线触发
MACA自愈机制,反复复位 BMC;- 最终导致
ipmcget/ipmcset所依赖的底层服务中断或运行时异常,执行时直接 core dump 或 无响应。
![]() 推荐优先分析
推荐优先分析 bmc_core 的 coredump 和日志,确认是否发生内存溢出或空指针访问。同时检查微组件在线状态和启动失败记录,综合判断系统是否处于“服务震荡”状态。
如能提供 coredump 文件及完整 dmesg 输出,可进一步精确定位崩溃调用链。
这个是联系谁解决吗?日志传递给谁了?
给芝奔和业胜都传递了
是BMC刚启动,就输入CLI命令的吗?这个可能是刚启动,CIL模块还没有加载成功导致的。此时,SSH已经可以正常使用了
并不是,出现问题的时候,是一直 coredump,直到 BMC 重启才恢复,并不是刚启动的时候无回显 coredump
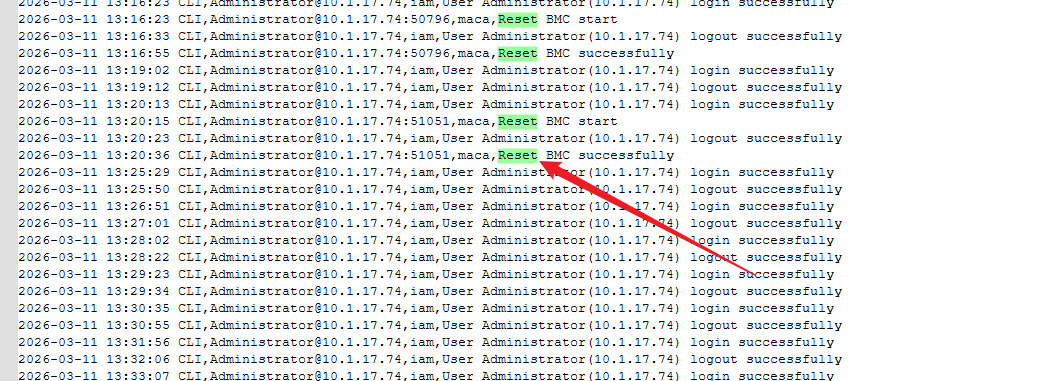
一键收集是问题发生后,就收集的吗? 能说下,2个日志包中,core文件的时间点吗?
我们是在长时间测试BMC Reset出现的这个问题,第5次就出现了这个问题
2512 ipmc命令coredump.tar.gz.txt (6.1 MB)
一键收集,把后缀名txt去掉就可以解压了
收到日志,我们团队成员会进行分析,结果会及时同步
帮忙确认下问题发生的时间点,第5次,reset的时间点?最好,能说明下发生问题时,BMC的时间点