问题描述
测试在做 Disk2、4、5 的硬盘热插拔测试,可是 Disk3 的磨损率却变成了0,触发告警,数小时后DC的时候才恢复,之后这块盘就没有再出现过告警了;
操作日志:
2026-03-04 16:28:23 NA,NA@127.0.0.1,storage,Disk4 plug out successfully
2026-03-04 16:28:50 NA,NA@127.0.0.1,storage,Disk4 plug in successfully
2026-03-04 16:28:56 NA,NA@127.0.0.1,storage,Disk4 plug out successfully
2026-03-04 16:29:40 NA,NA@127.0.0.1,storage,Disk4 plug in successfully
2026-03-04 16:29:47 NA,NA@127.0.0.1,storage,Disk4 plug out successfully
2026-03-04 16:30:50 NA,NA@127.0.0.1,storage,Disk4 plug in successfully
2026-03-04 16:31:01 NA,NA@127.0.0.1,storage,Disk5 plug out successfully
2026-03-04 16:32:24 NA,NA@127.0.0.1,storage,Disk5 plug in successfully
2026-03-04 16:32:32 NA,NA@127.0.0.1,storage,Disk5 plug out successfully
2026-03-04 16:33:12 NA,NA@127.0.0.1,storage,Disk5 plug in successfully
2026-03-04 16:35:29 NA,NA@127.0.0.1,storage,Disk2 plug out successfully
2026-03-04 16:35:37 NA,NA@127.0.0.1,storage,Disk4 plug out successfully
....
2026-03-04 20:43:50 CLI,Administrator@192.168.109.52:51435,fructrl,Set FRU0 to forced power off successfully
2026-03-04 20:43:53 N/A,HOST@localhost,host_agent,Set BMC hostname to () successfully
2026-03-04 20:44:15 CLI,Administrator@192.168.109.52:51435,fructrl,Set FRU0 to power on successfully
remote_log
2026-03-04 16:36:42,Major,0x0200001D,Asserted,The disk Disk3 remnant media wearout (0%) is lower than the threshold (5%) (SN:QB3H814400112).
......
2026-03-04 20:43:56,Major,0x0200001E,Deasserted,The disk Disk3 remnant media wearout (0%) is lower than the threshold (5%) (SN:QB3H814400112).
报剩余寿命为0的盘,其 DeviceId 为 178,观察日志打印可见盘的信息是有在以10分钟为周期刷新的,目标盘的信息也有在被刷新;
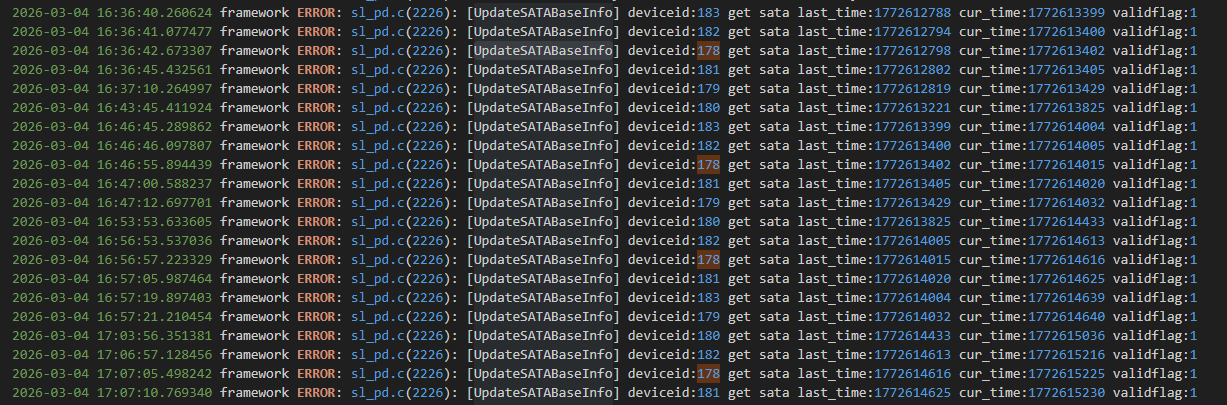
1、当前没有很好的定位思路,测试也未能复现问题;
2、测试没有保留当时的环境,是做了DC告警消除时,才发现之前有告警,才做了一键收集;
3、观察SML代码,RAID下挂盘的剩余寿命,基本就是从RAID卡获取的,代码中未看到明显的怀疑点;
4、有怀疑是不是BMA上报的(环境上有安装BMA),但是没有明显的此类打印,基本排除了;

求助:有没有更好的定位思路或者建议,是否有什么日志能够快速定界问题是在BMC侧还是介质侧?
一键收集.z02.txt (8 MB)
一键收集.z01.txt (8 MB)
一键收集.zip (2.7 MB)
环境信息
1230SP1版本