-- 示例伪代码
function read_nvme_model(slot)
local max_retries = 3
for i = 1, max_retries do
local vpd_data = try_read_vpd(slot)
if vpd_data and is_valid_vpd(vpd_data) then
local model = parse_model_from_vpd(vpd_data)
if model and string.len(model) > 4 then -- 过滤短/异常值
return model
end
end
sleep(500) -- 等待500ms重试
end
log:error("Failed to read valid model after retries")
return nil
end
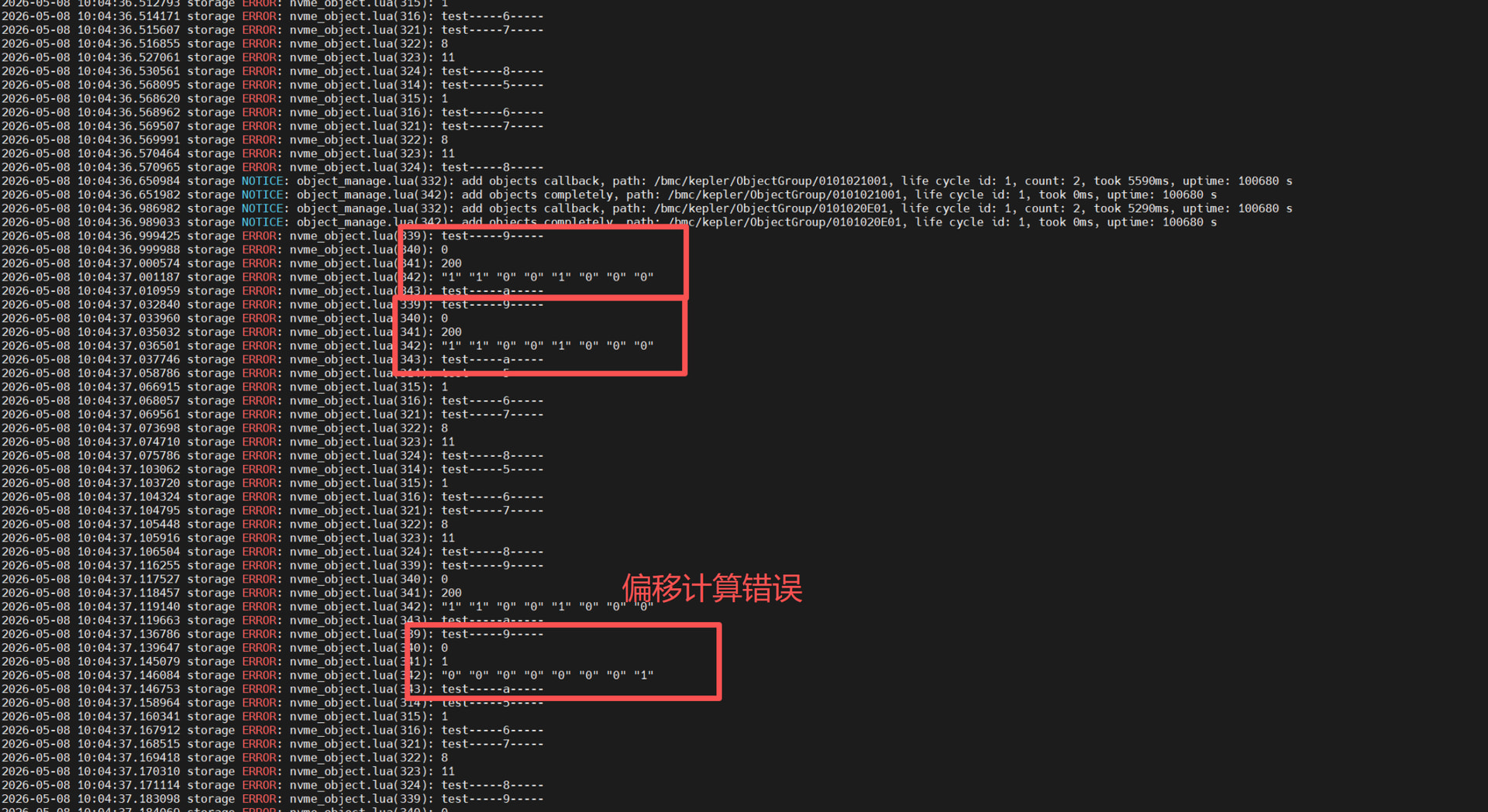
优点:提高容错性,避免因瞬时链路不稳定导致读取失败。
方案二:优先使用 BMA 上报信息进行兜底
BMA 通常在系统启动后上报 NVMe 盘的准确信息(包括型号、SN等):
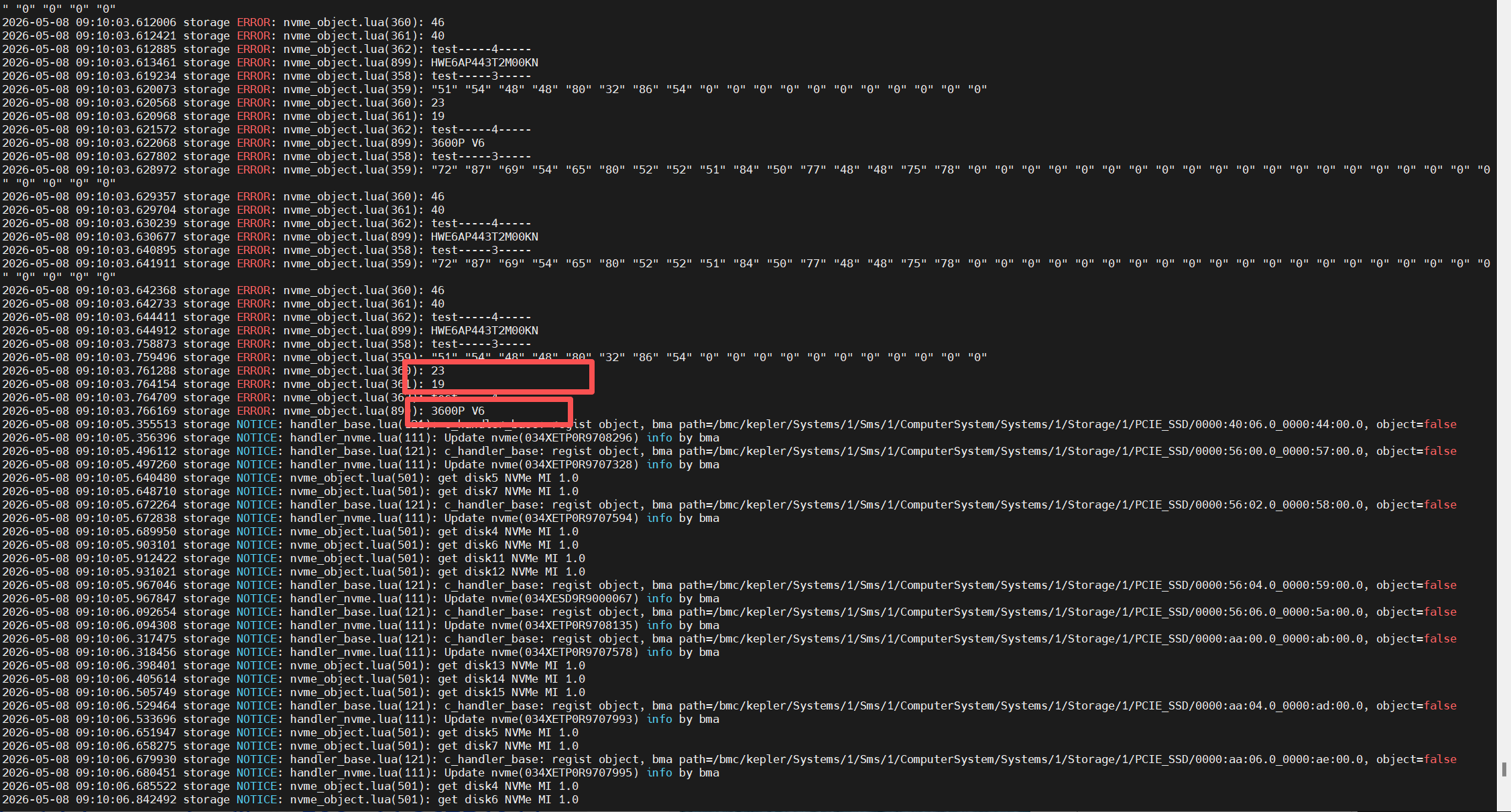
handler_nvme.lua(111): Update nvme(034XETPOR9708296) info by bma
建议:
允许 Drive 的 Model 字段支持“后期更新”机制。
初始读取失败时,先设置默认/临时值(如"Unknown"),等待 BMA 上报后再修正。
说明:这符合 openUBMC 中 Drive 对象的设计理念(抽象化槽位属性,支持动态更新)。
方案三:校验解析结果的合理性
在解析 Model 字段后,增加简单有效性检查:
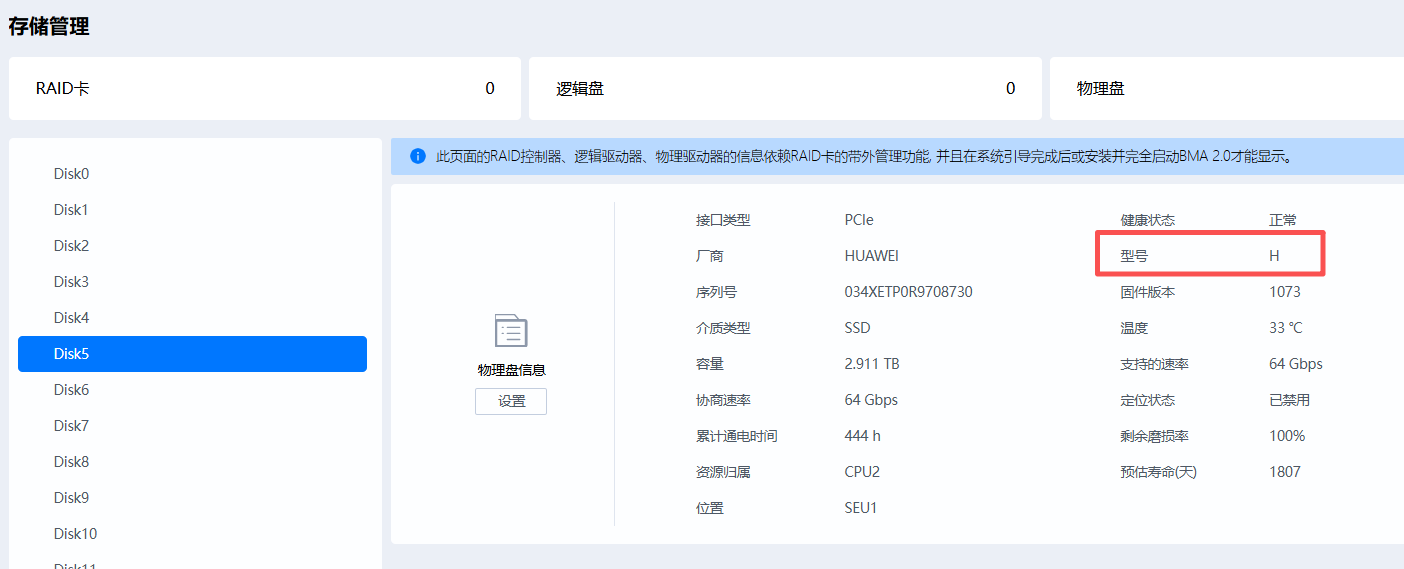
if model == nil or model == "" or #model < 5 or model == "H" then
log:warn("Invalid model detected: '"..tostring(model).."', using fallback")
return try_fallback_method() -- 如查表、使用默认值
end