问题背景
对NVMe盘做快速热插拔时storage概率性出现挂死
操作步骤
1、对直通NVMe盘进行快速热插拔(3秒以上)
2、观察NVMe盘的插拔日志能否显示
现象
插入日志约4分钟后才显示
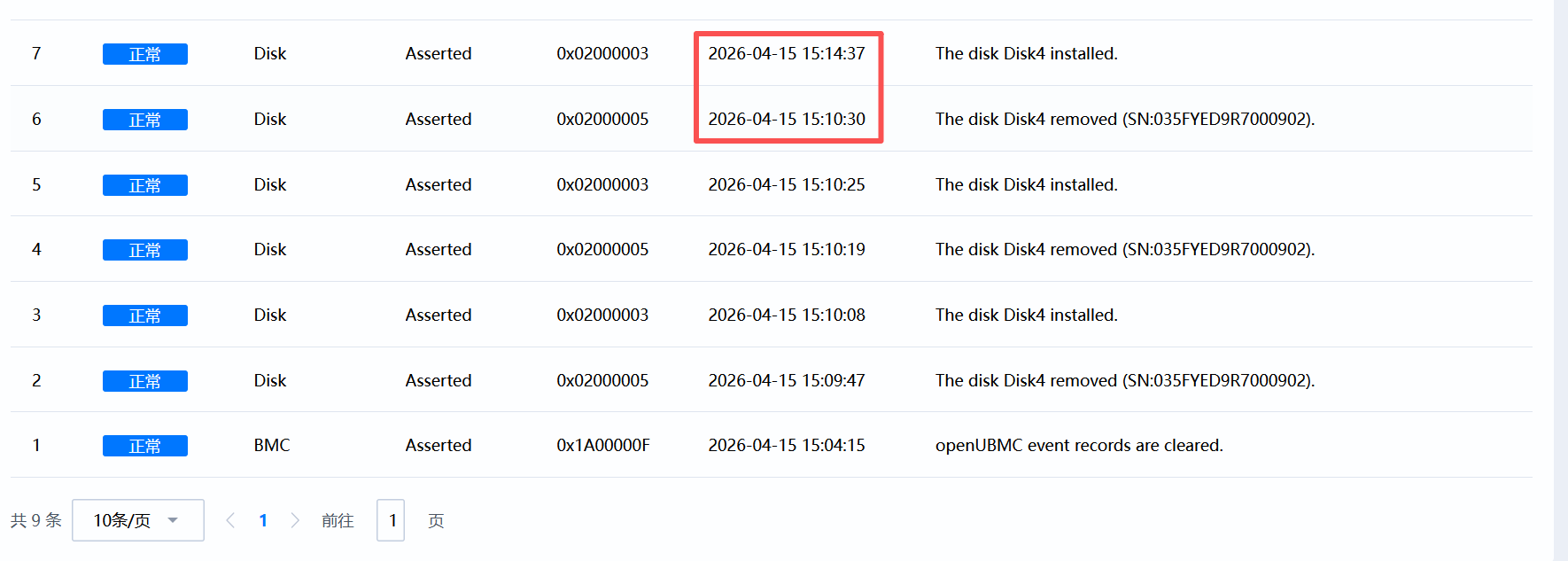
PS
通过mdbctl setprop set Scanner_Drive4PresentAccessor_010102 bmc.kepler.Scanner Value 1/0,快速修改NVMe的在位信号模拟插拔,也很容易复现该问题
初步分析
2026-04-15 15:10:19.189497 event NOTICE: hardware_event.lua(570): Event_Hdd5Insert_010102|{"value":[0],"type":"synchronization","source":{"properties":[{"Path":"/bmc/kepler/Systems/1/Storage/Drives/Drive_5_010102","Service":"bmc.kepler.storage","Interface":"bmc.kepler.Systems.Storage.Drive","Property":"Presence"}],"Default":255}}
2026-04-15 15:10:19.467001 event NOTICE: hardware_event.lua(570): Event_Hdd5Removed_010102|{"value":[0],"type":"synchronization","source":{"properties":[{"Path":"/bmc/kepler/Systems/1/Storage/Drives/Drive_5_010102","Service":"bmc.kepler.storage","Interface":"bmc.kepler.Systems.Storage.Drive","Property":"Presence"}],"Default":255}}
2026-04-15 15:10:19.481646 storage NOTICE: object_manage.lua(228): start to remove objects, path: /bmc/kepler/ObjectGroup/0101020101
2026-04-15 15:10:19.482202 storage NOTICE: object_manage.lua(234): start to DeleteObject Nvme_1_0101020101
2026-04-15 15:10:19.485545 storage NOTICE: drive_collection.lua(141): Nvme 4 is removed
2026-04-15 15:10:19.652084 storage NOTICE: pd_identify_service.lua(129): Disk4 del
2026-04-15 15:10:19.654204 storage NOTICE: drive_object.lua(615): Disk4 is_nvme turn false
2026-04-15 15:10:19.849572 storage ERROR: factory.lua(113): c_factory:del_object failed: unkonw class Nvme
2026-04-15 15:10:19.850329 storage NOTICE: object_manage.lua(234): start to DeleteObject ReplicaDrive_1_0101020101
2026-04-15 15:10:20.023073 storage ERROR: factory.lua(113): c_factory:del_object failed: unkonw class ReplicaDrive
2026-04-15 15:10:20.023734 storage NOTICE: object_manage.lua(252): remove objects completely, path: /bmc/kepler/ObjectGroup/0101020101
2026-04-15 15:10:20.024127 storage NOTICE: object_manage.lua(228): start to remove objects, path: /bmc/kepler/ObjectGroup/01010201
2026-04-15 15:10:20.024435 storage NOTICE: object_manage.lua(234): start to DeleteObject VirtualVPDConnect_01010201
2026-04-15 15:10:20.025787 storage NOTICE: vpd_connector_collection.lua(39): vpd connector 4 del
2026-04-15 15:10:20.034959 storage ERROR: factory.lua(113): c_factory:del_object failed: unkonw class VirtualVPDConnect
2026-04-15 15:10:20.037864 storage NOTICE: object_manage.lua(252): remove objects completely, path: /bmc/kepler/ObjectGroup/01010201
2026-04-15 15:10:25.530214 event NOTICE: hardware_event.lua(570): Event_Hdd5Insert_010102|{"value":[1],"type":"synchronization","source":{"properties":[{"Path":"/bmc/kepler/Systems/1/Storage/Drives/Drive_5_010102","Service":"bmc.kepler.storage","Interface":"bmc.kepler.Systems.Storage.Drive","Property":"Presence"}],"Default":255}}
2026-04-15 15:10:25.847278 storage NOTICE: object_manage.lua(312): start to add objects, path: /bmc/kepler/ObjectGroup/01010201, life cycle id: 1, count: 1, uptime: 444217 s
2026-04-15 15:10:25.884932 storage NOTICE: vpd_connector_collection.lua(35): vpd connector 4 add
2026-04-15 15:10:25.887158 storage NOTICE: object_manage.lua(332): add objects callback, path: /bmc/kepler/ObjectGroup/01010201, life cycle id: 1, count: 1, took 40ms, uptime: 444217 s
2026-04-15 15:10:25.890712 storage NOTICE: object_manage.lua(342): add objects completely, path: /bmc/kepler/ObjectGroup/01010201, life cycle id: 1, took 10ms, uptime: 444217 s
2026-04-15 15:10:25.913806 storage NOTICE: vpd_connector.lua(289): begin update_connector4
2026-04-15 15:10:25.956315 event NOTICE: hardware_event.lua(570): Event_Hdd5Removed_010102|{"value":[1],"type":"synchronization","source":{"properties":[{"Path":"/bmc/kepler/Systems/1/Storage/Drives/Drive_5_010102","Service":"bmc.kepler.storage","Interface":"bmc.kepler.Systems.Storage.Drive","Property":"Presence"}],"Default":255}}
2026-04-15 15:10:26.082109 storage NOTICE: pd_identify_service.lua(125): Disk4 add
2026-04-15 15:10:26.170214 storage NOTICE: vpd_connector.lua(229): connector4 classcode is 1, header_sum is 239, target sum is 239
2026-04-15 15:10:26.170593 storage NOTICE: vpd_connector.lua(267): connector get protocol is 0
2026-04-15 15:10:26.550948 storage NOTICE: object_manage.lua(312): start to add objects, path: /bmc/kepler/ObjectGroup/0101020101, life cycle id: 1, count: 2, uptime: 444217 s
2026-04-15 15:10:26.898927 storage NOTICE: drive_collection.lua(117): Nvme 4 is inserted
2026-04-15 15:10:26.902435 storage NOTICE: drive_collection.lua(134): NVMe :4 update system_id:1
2026-04-15 15:10:26.902866 storage NOTICE: drive_object.lua(571): Start update NVME static info, id:4 identify_pd:false.
2026-04-15 15:10:26.904001 storage NOTICE: drive_object.lua(621): Start update NVME info, id:4 identify_pd:false.
2026-04-15 15:10:26.904431 storage NOTICE: drive_object.lua(622): Disk4 is_nvme turn true
2026-04-15 15:10:27.171557 storage NOTICE: nvme_object.lua(272): NVMe4 load nvme-mi
2026-04-15 15:10:28.676774 storage NOTICE: nvme_object.lua(494): get disk4 NVMe MI 1.0
2026-04-15 15:10:29.046550 storage NOTICE: nvme_object.lua(494): get disk4 NVMe MI 1.0
2026-04-15 15:10:29.726975 storage ERROR: nvme_object.lua(555): get_multirecord_item_offset_len: Read chip failed
2026-04-15 15:10:29.727533 storage ERROR: nvme_object.lua(648): Read chip failed
2026-04-15 15:10:30.576438 event NOTICE: hardware_event.lua(570): Event_Hdd5Insert_010102|{"value":[0],"type":"synchronization","source":{"properties":[{"Path":"/bmc/kepler/Systems/1/Storage/Drives/Drive_5_010102","Service":"bmc.kepler.storage","Interface":"bmc.kepler.Systems.Storage.Drive","Property":"Presence"}],"Default":255}}
2026-04-15 15:10:30.769701 event NOTICE: hardware_event.lua(570): Event_Hdd5Removed_010102|{"value":[0],"type":"synchronization","source":{"properties":[{"Path":"/bmc/kepler/Systems/1/Storage/Drives/Drive_5_010102","Service":"bmc.kepler.storage","Interface":"bmc.kepler.Systems.Storage.Drive","Property":"Presence"}],"Default":255}}
2026-04-15 15:11:23.584565 maca ERROR: init.lua(62): [storage]HealthCheck failed, error: org.freedesktop.DBus.Error.NoReply: Did not receive a reply. Possible causes include:the remote application did not send a reply, the messagebus security policy blocked the reply, the reply timeout expired,or the network connection was broken.
2026-04-15 15:11:23.650313 maca ERROR: init.lua(98): component[storage] is in an abnormal status 1 times
2026-04-15 15:12:53.744736 maca ERROR: init.lua(62): [storage]HealthCheck failed, error: org.freedesktop.DBus.Error.NoReply: Did not receive a reply. Possible causes include:the remote application did not send a reply, the messagebus security policy blocked the reply, the reply timeout expired,or the network connection was broken.
2026-04-15 15:12:53.838197 maca ERROR: init.lua(98): component[storage] is in an abnormal status 2 times
2026-04-15 15:14:23.924241 maca ERROR: init.lua(62): [storage]HealthCheck failed, error: org.freedesktop.DBus.Error.NoReply: Did not receive a reply. Possible causes include:the remote application did not send a reply, the messagebus security policy blocked the reply, the reply timeout expired,or the network connection was broken.
2026-04-15 15:14:24.026783 maca ERROR: init.lua(91): component[storage] is in an abnormal status 3 times, and it will attempt to restart for recovery
可以看到15:10:30之后storage组件就挂死了,maca在15:14:24对storage进行重启后才恢复
2026-04-15 15:10:30.460207 [:00000010] hardware: lua call [0 to :10 : 1572206 msgsz = 0] error : [31m/opt/bmc/skynet/lualib/skynet.lua:0: org.freedesktop.DBus.Error.UnknownInterface: Unknown interface bmc.kepler.Connector stack traceback: [C]: in function 'error' ./opt/bmc/libmc/lualib/mc/app_preloader.lua:74: in function '' /opt/bmc/skynet/lualib/skynet.lua: in function </opt/bmc/skynet/lualib/skynet.lua:0> stack traceback: [C]: in function 'error' /opt/bmc/lualib/compat53/module.lua:176: in function '' /opt/bmc/skynet/lualib/skynet.lua: in function </opt/bmc/skynet/lualib/skynet.lua:0>[0m
2026-04-15 15:11:05.656191 [:00000000] hardware: A message from [ :00000008 ] to [ :0000000f ] maybe in an endless loop (version = 6244063)
2026-04-15 15:11:35.671773 [:00000000] hardware: A message from [ :00000008 ] to [ :0000000f ] maybe in an endless loop (version = 6244063)
2026-04-15 15:12:05.696600 [:00000000] hardware: A message from [ :00000008 ] to [ :0000000f ] maybe in an endless loop (version = 6244063)
2026-04-15 15:12:35.731128 [:00000000] hardware: A message from [ :00000008 ] to [ :0000000f ] maybe in an endless loop (version = 6244063)
2026-04-15 15:13:05.758759 [:00000000] hardware: A message from [ :00000008 ] to [ :0000000f ] maybe in an endless loop (version = 6244063)
2026-04-15 15:13:35.807505 [:00000000] hardware: A message from [ :00000008 ] to [ :0000000f ] maybe in an endless loop (version = 6244063)
2026-04-15 15:14:05.827521 [:00000000] hardware: A message from [ :00000008 ] to [ :0000000f ] maybe in an endless loop (version = 6244063)
2026-04-15 15:14:24.890290 [:00000012] interface: May overload, message queue length = 1994
2026-04-15 15:14:25.596657 [:00000002] hardware: LAUNCH snlua bootstrap
2026-04-15 15:14:25.680125 [:00000003] hardware: LAUNCH snlua launcher
2026-04-15 15:14:25.721082 [:00000004] hardware: LAUNCH snlua cdummy
2026-04-15 15:14:25.768661 [:00000005] hardware: LAUNCH harbor 0 4
2026-04-15 15:14:25.772348 [:00000006] hardware: LAUNCH snlua datacenterd
2026-04-15 15:14:25.813286 [:00000007] hardware: LAUNCH snlua service_mgr
2026-04-15 15:14:25.857467 [:00000008] hardware: LAUNCH snlua hica/subsys/hardware/service/main
2026-04-15 15:14:25.899262 [:00000009] hardware: LAUNCH snlua sd_bus
2026-04-15 15:14:26.590463 [:0000000a] hardware: LAUNCH snlua harbor
2026-04-15 15:14:26.701815 [:00000002] hardware: KILL self
2026-04-15 15:14:26.703892 [:0000000b] hardware: LAUNCH snlua general_hardware/service/main
2026-04-15 15:14:26.705095 [:0000000c] hardware: LAUNCH snlua network_adapter/service/main
2026-04-15 15:14:26.716270 [:0000000d] hardware: LAUNCH snlua mctpd/service/main
2026-04-15 15:14:26.726051 [:0000000e] hardware: LAUNCH snlua lsw/service/main
2026-04-15 15:14:26.742477 [:0000000f] hardware: LAUNCH snlua storage/service/main
2026-04-15 15:14:26.746193 [:00000010] hardware: LAUNCH snlua chassis/service/main
2026-04-15 15:14:28.832292 [:00000012] hardware: LAUNCH snlua mctpd/service/write_service
2026-04-15 15:14:29.024503 [:00000013] hardware: LAUNCH snlua mctpd/service/smbus_write_read_service
通过framework.log可以看到hardware: A message from [ :00000008 ] to [ :0000000f ] maybe in an endless loop (version = 6244063),证明确实陷入死循环了
求助内容
想问一下这类问题如何进行进一步的分析定位