l00012320
2026 年2 月 6 日 06:10
1
2026-01-09 02:25:44.204792 storage ERROR: app_preloader.lua(64): co[thread: 0x2aac1f0ca788] abnormal exit, err: kepler.class.ObjectDuplicateDefined: Class DiskArray’s object /bmc/kepler/Systems/1/Storage/Controllers/Controller_1_0101010A03/DiskArrays/5 duplicate defined.
日志打印显示task任务在初始状态后,10%之后,尝试创建DiskArray对象重复,然后应该是将整个线程崩掉了。但是TASK对象依然存在,也还在树上。
有两部分内容的疑问。
Task对象意外崩掉后,有没有机制能够进行任务回收?目前看虽然task_mgmt在storage组件,但是上树或者其它动作应该都是在闭源里的;
DiskArrays对象重复的原因是什么?添加逻辑盘时也不需要指定DiskArrayID,均由代码进行处理,这部分需要考虑加固一下。
答案内容由AI生成,仅供参考:
-- 伪代码示例
if not object_exists(path) then
register_object(path, class_name)
else
log:warning("Object already exists: %s", path)
-- 可选择 reload 或 skip
end
使用 UUID 或结合 Controller ID、Array ID 构造全局唯一路径。
避免直接使用简单的整数索引作为唯一标识。
分离 PCIeDevice 与 Controller 的加载流程,保证 DeviceName Slot 分配完成后,再初始化依赖它的 DiskArray。
功能
实现方式
异常捕获 在任务执行主流程包裹 pcall 或 xpcall,捕获异常并记录堆栈。
状态更新 异常时强制设置:
.State = "Exception".EndTime = now().Message = "ObjectDuplicateDefined" |自动清理 | 定期扫描长时间处于 Running 状态的任务,并结合线程存活状态判断是否“僵尸任务”,予以清理。 |事件上报 | 触发 TaskFailed 事件供上层告警系统订阅。 |
task_mgmt.lua 模块统一管理。
Create Logical Disk 流程
步骤
加固建议
1. 接收参数
校验 ArrayId 是否有效,是否已加载
2. 获取 DiskArray
查询资源树 /DiskArray/<id> 是否存在,复用而非重建
3. 创建逻辑盘
调用 CreateLogicalDriveOnExistedArray 方法(已有支持)
4. 更新状态
成功后更新 .Progress 至 100,并设置 .State = "Completed"
点击此处查看详细分析解答
根据提供的日志和系统信息,创建逻辑盘对象过程中出现概率性超时,其根本原因在于 DiskArray 对象重复注册导致任务线程异常退出
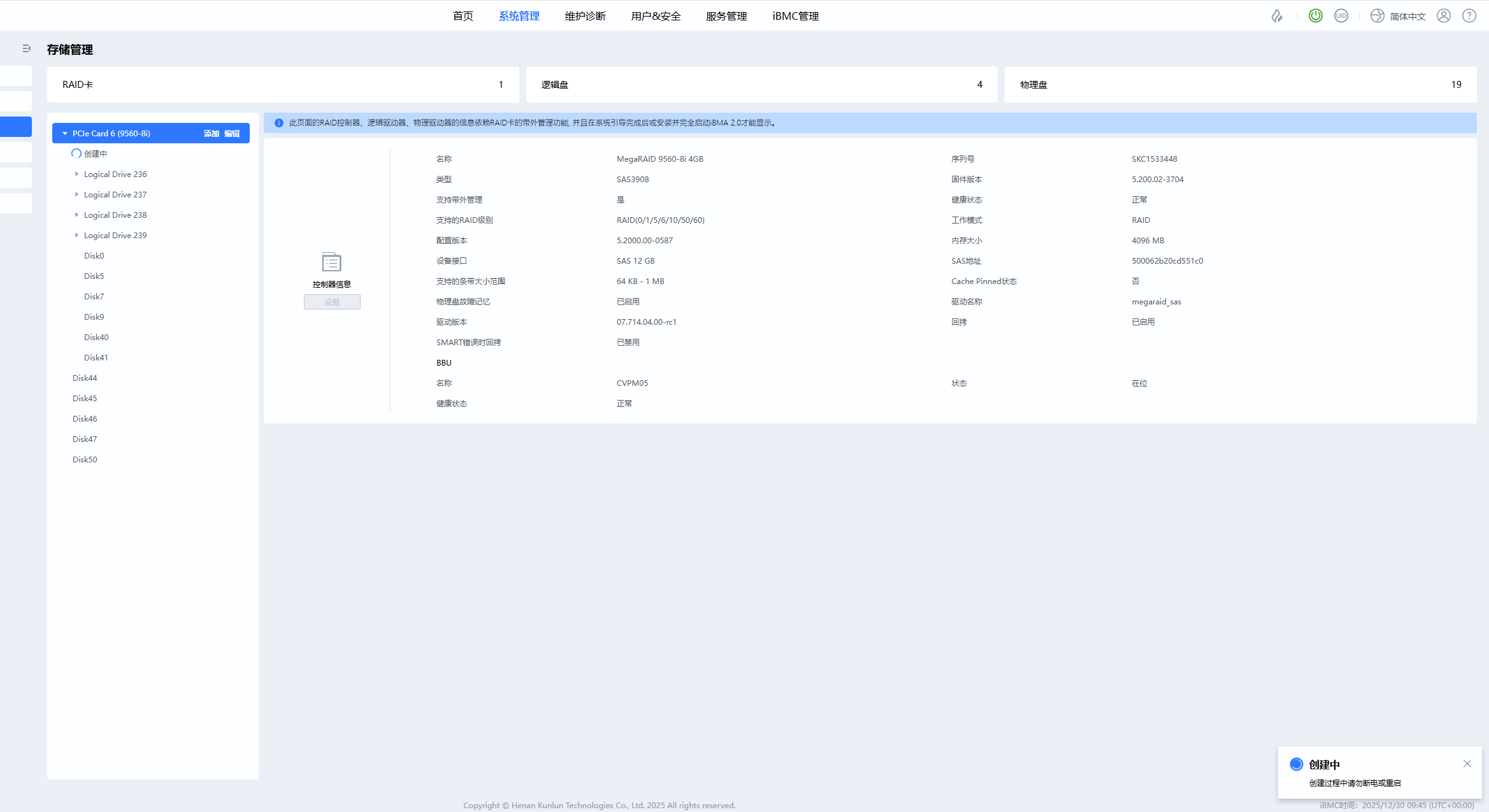
用户在 Web 界面尝试创建逻辑盘(Logical Drive),系统显示“创建中”。
操作日志中记录了任务(Task)的启动和初始执行阶段:
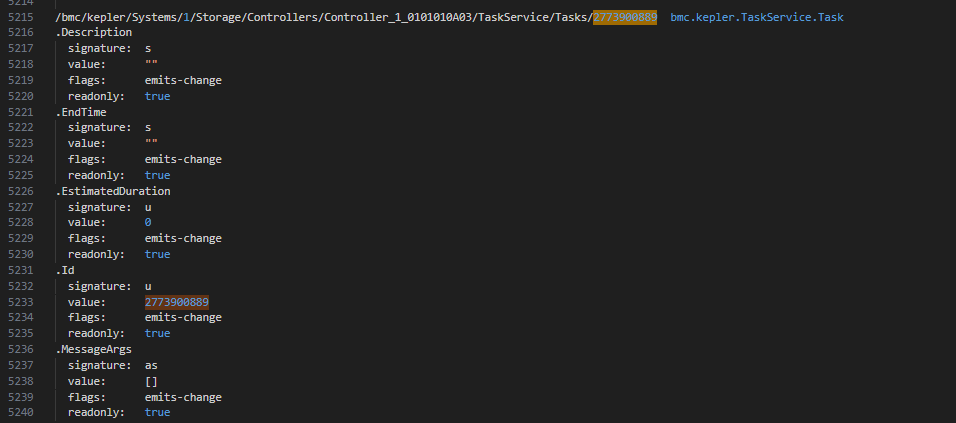
任务 ID:2773900889
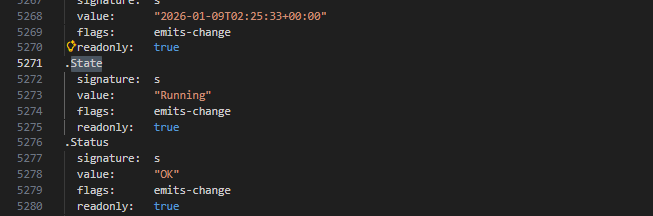
状态从 New 更新为 Running
进度推进至 10%
随后关键错误日志出现:ERROR: app_preloader.lua(64): abnormal exit, err: kepler.class.ObjectDuplicateDefined: Class DiskArray's object /bmc/kepler/Systems/1/Storage/Controllers/Controller_1_0101010A03/DiskArrays/5 is already registered
任务线程崩溃,但 Task 对象仍存在于资源树中,状态未更新为失败或完成,造成“悬空任务”。
DiskArray 对象重复定义的原因DiskArray 实体说明
实体定义 :bmc.kepler.Systems.Storage.DiskArray 是一个管理 RAID 组配置和元数据的系统级对象。关键属性 :
Id:RAID 组唯一编号(由 RAID 卡读取)RefVolumes:关联的逻辑盘列表UsedSpaceMiB, TotalFreeSpaceMiB:空间使用情况
从日志可见:
Class DiskArray's object /bmc/kepler/Systems/1/Storage/Controllers/Controller_1_0101010A03/DiskArrays/5 is already registered
表明系统试图再次注册一个已存在的 DiskArray 实例,违反了对象唯一性原则。
原因
分析
持久化数据冲突 在系统启动或任务执行过程中,DiskArray 对象可能已被先前的流程加载进内存数据库。当创建新逻辑盘时再次尝试加载同一 DiskArray,导致主键冲突。这与搜索结果中提到的“ORM对象创建时主键值与已有数据冲突”一致。
多线程/异步加载竞争 update_drive_slot_info() 等定时任务与其他 RAID 初始化任务并发执行,可能导致对 DiskArray 的重复处理。
Controller 加载时序问题 如搜索结果 #3 所述,Controller 和 PCIeDevice 在同一 CSR 中同时处理,存在加载时序依赖风险。若 DiskArray 的初始化依赖未完成即被访问,可能触发重复注册尝试。
Cache/Session 脏数据残留 上次操作未完全清理资源树路径,导致新任务误判需重新创建对象。
尽管线程异常退出(abnormal exit),但:
任务对象仍然存在于资源树中;
没有自动将 .State 更新为 Exception 或 Failed;
没有触发 .EndTime 设置与事件上报。
结论 :当前系统缺乏对“任务执行线程崩溃”的异常捕获与善后处理机制。
项目
内容
直接原因 创建逻辑盘过程中尝试重复注册已存在的 DiskArray 对象,引发 ObjectDuplicateDefined 异常,导致协程异常退出。
根本原因 - 对象注册缺乏幂等控制(缺少“是否存在”检查)
影响范围 所有涉及 DiskArray 访问的操作,如创建逻辑盘、刷新阵列信息等,均可能概率性失败。
-- 伪代码示例
if not object_exists(path) then
register_object(path, class_name)
else
log:warning("Object already exists: %s", path)
-- 可选择 reload 或 skip
end
使用 UUID 或结合 Controller ID、Array ID 构造全局唯一路径。
避免直接使用简单的整数索引作为唯一标识。
分离 PCIeDevice 与 Controller 的加载流程,保证 DeviceName Slot 分配完成后,再初始化依赖它的 DiskArray。
功能
实现方式
异常捕获 在任务执行主流程包裹 pcall 或 xpcall,捕获异常并记录堆栈。
状态更新 异常时强制设置:
.State = "Exception".EndTime = now().Message = "ObjectDuplicateDefined" |自动清理 | 定期扫描长时间处于 Running 状态的任务,并结合线程存活状态判断是否“僵尸任务”,予以清理。 |事件上报 | 触发 TaskFailed 事件供上层告警系统订阅。 |
task_mgmt.lua 模块统一管理。
Create Logical Disk 流程
步骤
加固建议
1. 接收参数
校验 ArrayId 是否有效,是否已加载
2. 获取 DiskArray
查询资源树 /DiskArray/<id> 是否存在,复用而非重建
3. 创建逻辑盘
调用 CreateLogicalDriveOnExistedArray 方法(已有支持)
4. 更新状态
成功后更新 .Progress 至 100,并设置 .State = "Completed"
CreateVolumeInExistingArrayArrayId, Capacity, RaidType 等。CreateLogicalDriveOnExistedArray
/bmc/kepler/Systems/1/
└─ Storage/
└─ Controllers/
└─ Controller_1_0101010A03/
├─ DiskArray/0 → RAID组信息(Id, RefVolumes, 空间等)
├─ LogicalDrives/ → 逻辑盘列表
└─ TaskService/
└─ Tasks/2773900889 → 当前任务对象
问题
建议措施
DiskArray 重复注册增加存在性判断逻辑,避免重复加载;优化 CSR 解析时序
任务崩溃后悬空
增强异常捕获机制,实现状态回写与自动回收
概率性超时
引入幂等性控制、资源预检、并发锁机制,提升稳定性
最终目标 :构建健壮、可追溯、可恢复 的存储管理任务体系,避免因底层对象冲突导致用户操作失败且无法感知。
文档参考来源:
bmc.kepler.Systems.Storage.DiskArray 实体描述CreateLogicalDriveOnExistedArray 方法定义搜索结果中关于持久化冲突、主键冲突、任务管理等问题分析
相关链接:
【问题求助】【storage】背板csr中硬盘槽位配置进行调整后,web界面概率出现卡对象重复出现 【storage】【问题求助】双raid卡时概率 性有一张raid 卡 数据信息无法刷新成功 偶现raid卡 9560-8i通信异常触发告警,一段时间后又消除告警 后置背板上的两个硬盘组raid失败 上下电常见问题指南 | 文档中心 | openUBMC
1.需要在可能存在抛错的流程中pcall,防止意外退出,没有正确更新Task的状态与进度。
修复创建RAID逻辑盘概率性卡住-storage-AtomGit | GitCode