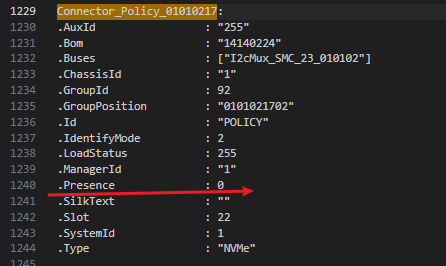
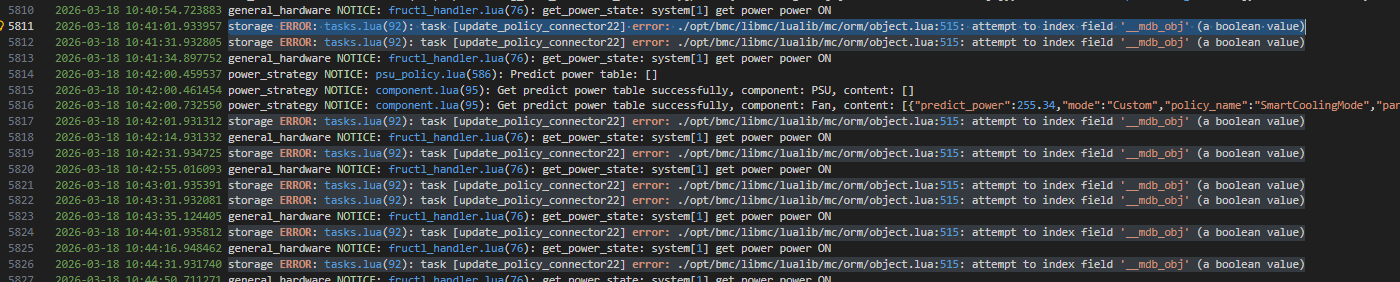
有相关日志报错,应该是没有走入正常流程:
storage ERROR: tasks.lua(92): task [update_policy_connector22] error: ./opt/bmc/libmc/lualib/mc/orm/object.lua:515: attempt to index field ‘__mdb_obj’ (a boolean value)
storage ERROR: tasks.lua(92): task [update_policy.connector22] error:
./opt/bmc/libmc/lualib/mc/orm/object.lua:515:
attempt to index field '__mdb_obj' (a boolean value)
-- 伪代码示意:tasks.lua 中 update_policy 任务逻辑
function update_policy(connector_id)
local obj = orm.get_object(connector_id) -- 返回 false 或 nil
if not obj then return end
-- 尝试访问 obj.__mdb_obj 字段(但 obj 可能是 boolean)
local mdb = obj.__mdb_obj -- ← 报错点:attempt to index field (boolean)
...
end
-- 在 tasks.lua 中增加:
local obj = orm.get_object(connector_id)
if not obj then
log.error("Failed to get ORM object for connector %s", connector_id)
return
end
if type(obj) ~= "table" then
log.error("ORM object for connector %s is invalid type: %s", connector_id, type(obj))
return
end
function c_vpd_connect:dtor()
local task_name = string.format('update_vpd_connector%s', self.Slot)
local task = c_tasks.get_instance():get_task(task_name)
if task then
task:stop()
end
end
function c_vpd_connect:dtor()
local task_name = string.format('update_vpd_connector%s', self.Slot)
local task = c_tasks.get_instance():get_task(task_name)
if task then
task:stop()
end
end