问题背景
目前我们在适配一款gpu,配置完sr的Chip之后尝试手动发命令获取温度
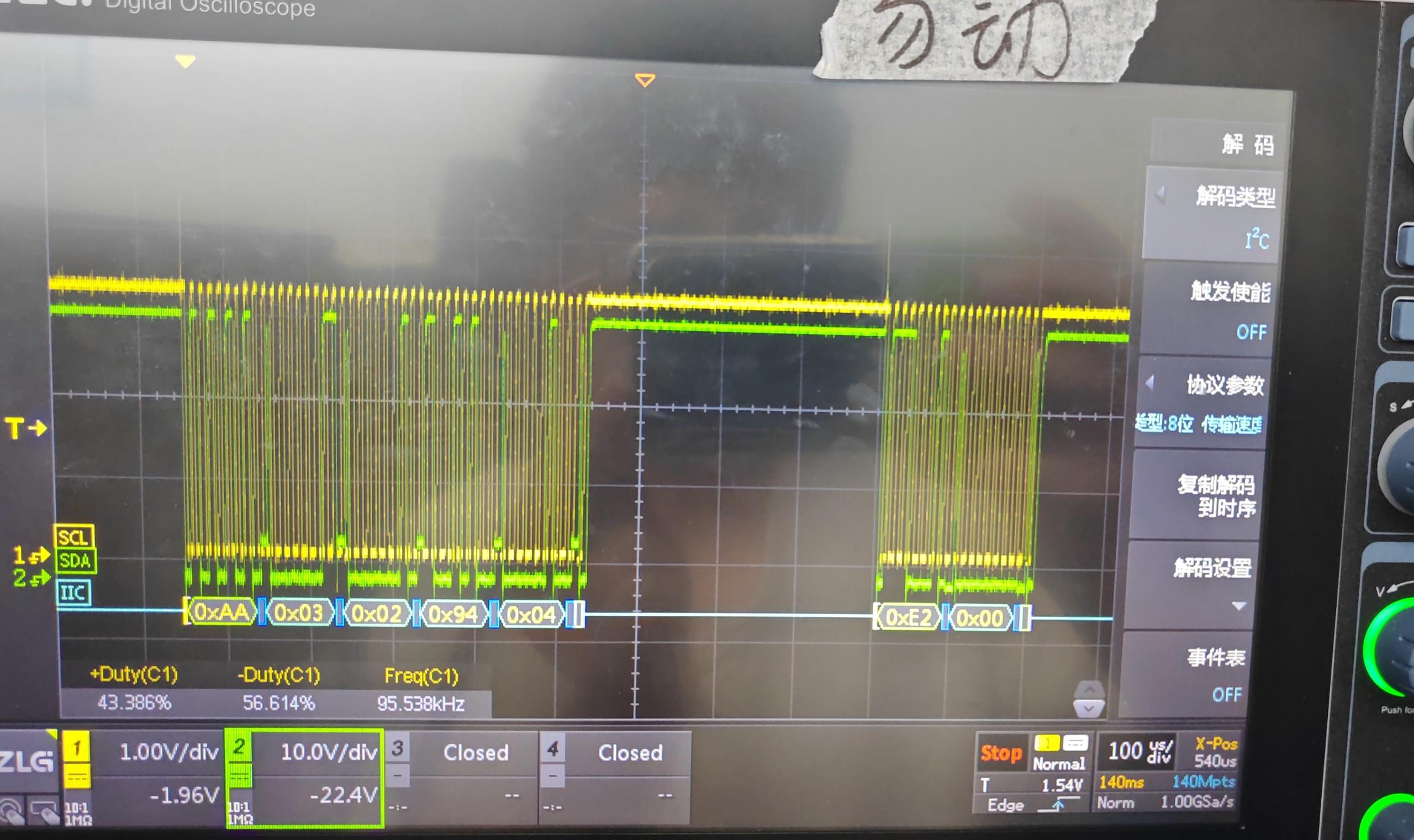
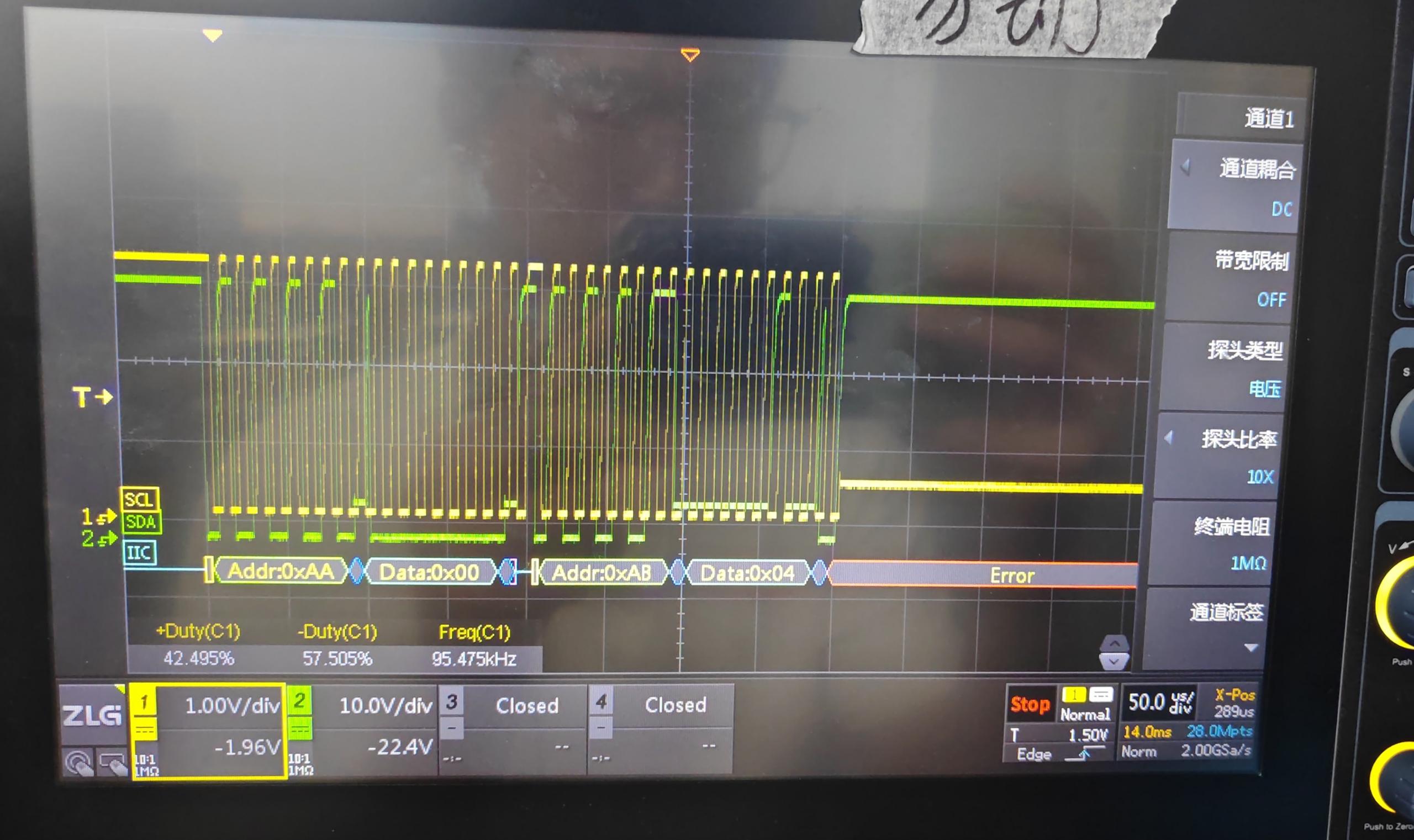
出现bmc挂死 问题
波 形如下
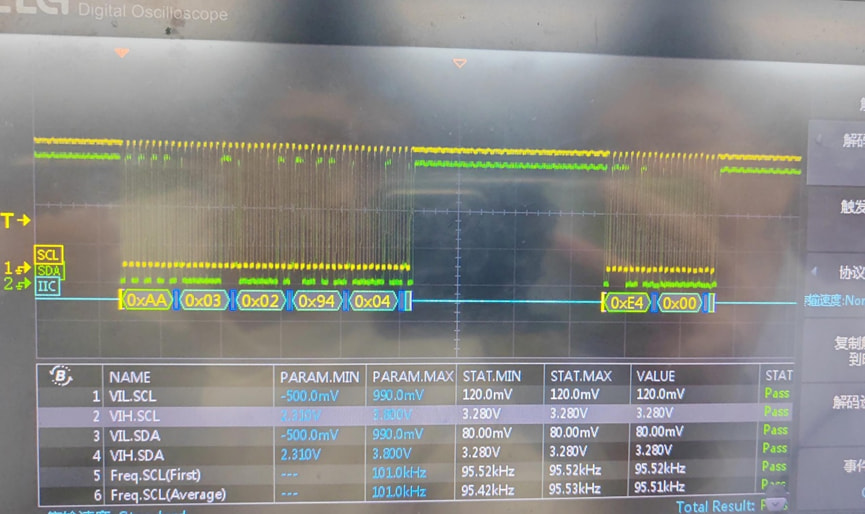
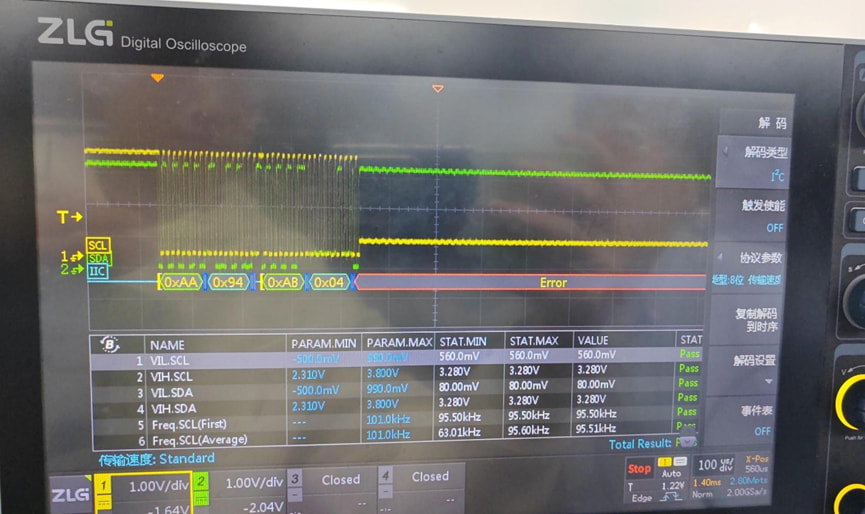
后经过厂家分析, 是读步骤时序问题
厂家时序如下
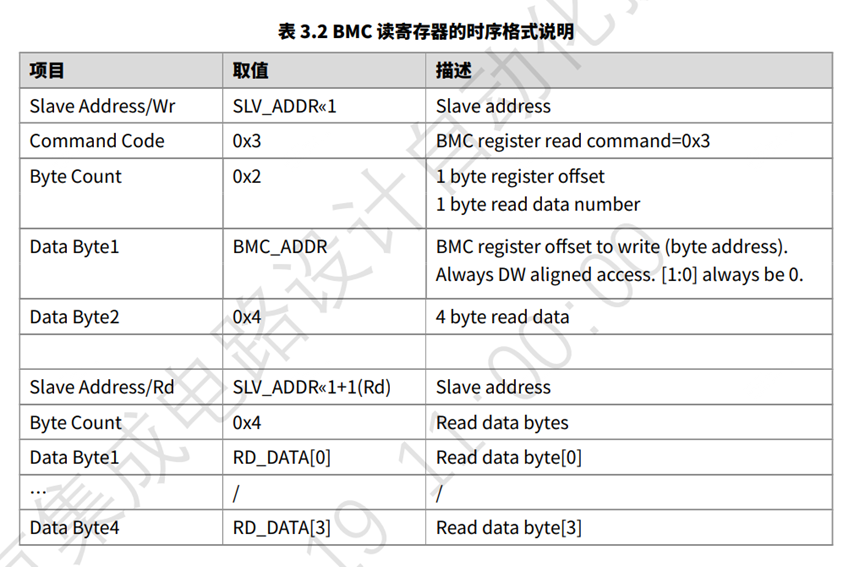
发送读命令的时候,不能跟cmd ,只能是地址+长度
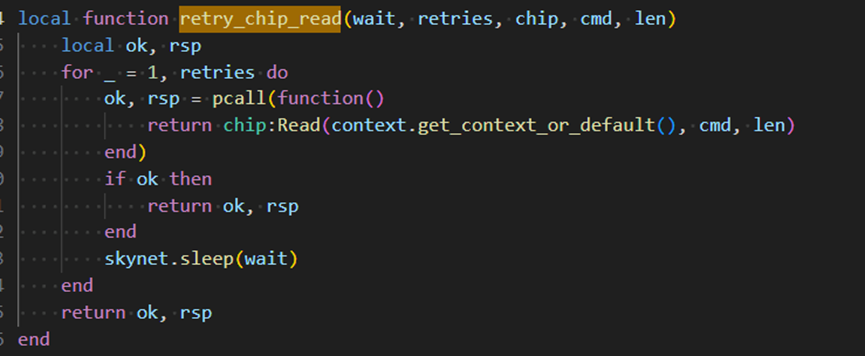
查看bmc接口,chip:read后面必须跟cmd,len。厂家要求不跟cmd,求助是 否有方案规避
已经尝试过的方案
Cmd传 0进去,还是失败
目前我们在适配一款gpu,配置完sr的Chip之后尝试手动发命令获取温度
出现bmc挂死 问题
波 形如下
后经过厂家分析, 是读步骤时序问题
厂家时序如下
发送读命令的时候,不能跟cmd ,只能是地址+长度
查看bmc接口,chip:read后面必须跟cmd,len。厂家要求不跟cmd,求助是 否有方案规避
Cmd传 0进去,还是失败
答案内容由AI生成,仅供参考:
| 方案 | 是否可行 | 推荐度 | 说明 |
|---|---|---|---|
直接调用 Read(0, len) |
不推荐 | 厂家不接受带cmd操作 | |
使用 ComboWriteRead |
★★★★★ | 最灵活,可完全控制I²C帧 | |
| 封装自定义读函数 | ★★★★☆ | 需确认底层是否允许 | |
| 分步写+读 | ★★★★☆ | 易于调试,但效率较低 |
优先使用 ComboWriteRead 接口,严格按照厂家时序构造请求包,避免因接口封装导致的不兼容问题。
同时建议在 gpu_service.lua 中增加对该GPU型号的专用读取函数,以确保未来固件升级时能持续支持该特殊协议。
在适配一款GPU卡(GPU_X201)时,配置完SR文件中的Chip后尝试通过BMC手动发送命令获取温度信息,但出现BMC挂死问题。经过厂家分析,确认问题根源为读寄存器的时序不符合设备要求。
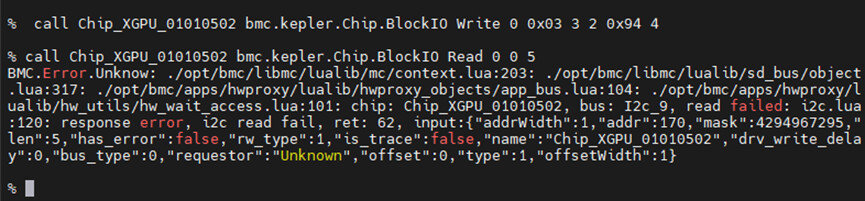
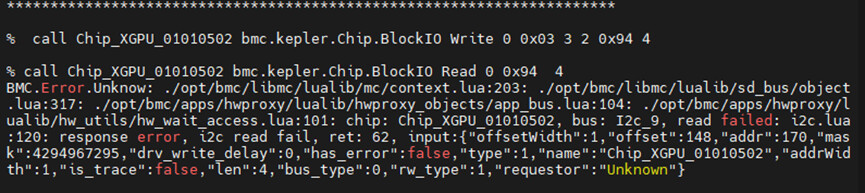
% call chip_XGPU_01010502 bmc.kepler.chip.BlockIO Write 0 0x94 3 2 0x94 4
该命令尝试使用标准的I²C写入流程,但在执行过程中出现了通信失败:
ret: 62 (I²C通信失败)i2c write failchip_XGPU_01010502| 步骤 | 内容 |
|---|---|
| 1. Slave Address/Wr | SLV_ADDR << 1 |
| 2. Command Code | 0x03(固定读命令) |
| 3. Byte Count | 0x02 |
| 4. Data Byte1 | BMC寄存器偏移地址(如 0x94) |
| 5. Data Byte2 | 要读取的数据字节数(如 0x04) |
| 6. Slave Address/Rd | SLV_ADDR << 1 + 1 |
| 7. Byte Count | 0x04 |
| 8. Data Byte[1~4] | 返回的4字节数据 |
关键点:读操作不能直接带
cmd参数,只能是“地址+长度”。
从提供的代码片段可以看出:
local function retry_chip_read(wait, retries, chip, cmd, len)
return chip:Read(context.get_context_or_default(), cmd, len)
end
chip:Read(...) 接口强制要求传入 cmd 和 len 参数。cmd = 0 传入仍失败,说明底层驱动未适配此特殊时序。| 对比项 | 厂家要求 | 当前BMC实现 |
|---|---|---|
| 读命令结构 | 地址 + 长度(无操作码) | 必须包含cmd字段 |
| Command Code | 固定为0x03 | 可变,由调用方指定 |
| 是否支持无cmd读取 | ||
| 底层协议封装 | 灵活控制I²C帧 | 封装过死 |
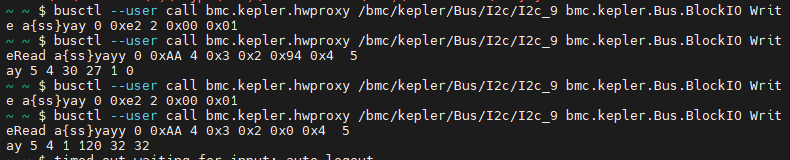
ComboWriteRead 接口绕过限制(推荐)利用 bmc.kepler.Chip.BlockIO.ComboWriteRead 接口,直接构造符合厂家要求的完整I²C事务。
busctl --user call bmc.kepler.hwproxy /bmc/kepler/Chip/Complex/Chip_XGPU_01010502 \
bmc.kepler.Chip.BlockIO ComboWriteRead "a{ss}uayuu" \
0 3 2 0x94 0x04 4 4
a{ss}: 保留字段,填 0u: 3 → Command Code(即0x03)ay: 2 0x94 0x04 → 字节计数(2) + 偏移地址(0x94) + 读取长度(4)u: 4 → 实际期望读取长度u: 4 → 返回数据长度
此方式完全绕过
Read(cmd, len)接口,直接构造底层I²C帧,可满足厂家特殊时序要求。
在 gpu_service.lua 或相关驱动中封装一个自定义函数,始终使用固定cmd=0x03发起读取。
function custom_gpu_read(chip, offset, length)
local cmd = 0x03 -- 强制使用厂家规定命令
local ok, rsp = pcall(function()
return chip:Read(context.get_context_or_default(), cmd, length)
end)
if not ok then
log.error("GPU read failed at offset 0x%x", offset)
return nil
end
return rsp
end
若Combo接口不可用,可先用 Write 设置读命令和参数,再用 Read 获取数据。
busctl --user call bmc.kepler.hwproxy /bmc/kepler/Chip/Complex/Chip_XGPU_01010502 \
bmc.kepler.Chip.BlockIO Write "a{ss}uay" 0 3 2 0x94 0x04
busctl --user call bmc.kepler.hwproxy /bmc/kepler/Chip/Complex/Chip_XGPU_01010502 \
bmc.kepler.Chip.BlockIO Read "a{ss}uu" 0 0 4
该方法模拟完整的“写命令+读数据”流程,适用于需要分步调试的场景。
busctl introspect 查看接口能力busctl introspect --user bmc.kepler.hwproxy /bmc/kepler/Chip/Complex/Chip_XGPU_01010502
确认是否存在以下接口:
ComboWriteReadBatchWriteWrite / Read| 方案 | 是否可行 | 推荐度 | 说明 |
|---|---|---|---|
直接调用 Read(0, len) |
不推荐 | 厂家不接受带cmd操作 | |
使用 ComboWriteRead |
★★★★★ | 最灵活,可完全控制I²C帧 | |
| 封装自定义读函数 | ★★★★☆ | 需确认底层是否允许 | |
| 分步写+读 | ★★★★☆ | 易于调试,但效率较低 |
优先使用 ComboWriteRead 接口,严格按照厂家时序构造请求包,避免因接口封装导致的不兼容问题。
同时建议在 gpu_service.lua 中增加对该GPU型号的专用读取函数,以确保未来固件升级时能持续支持该特殊协议。
可以学习这里面的插件机制,自己定义相关读写操作,不过需要注意避免影响到其他gpu
/general_hardware/include/hwproxy/plugins/general_hardware/init.lua
可以尝试一下直接使用总线调试接口
![]()
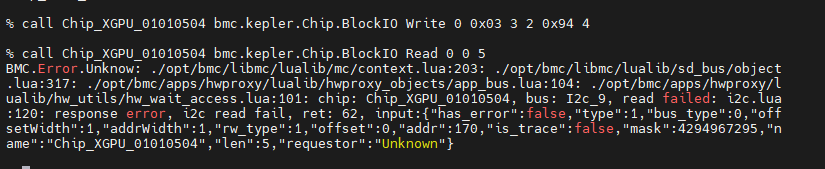
这个Read命令对应的波形图发一下,应该不是帖子里的那2个吧?因为这条命令不涉及0x94的信息
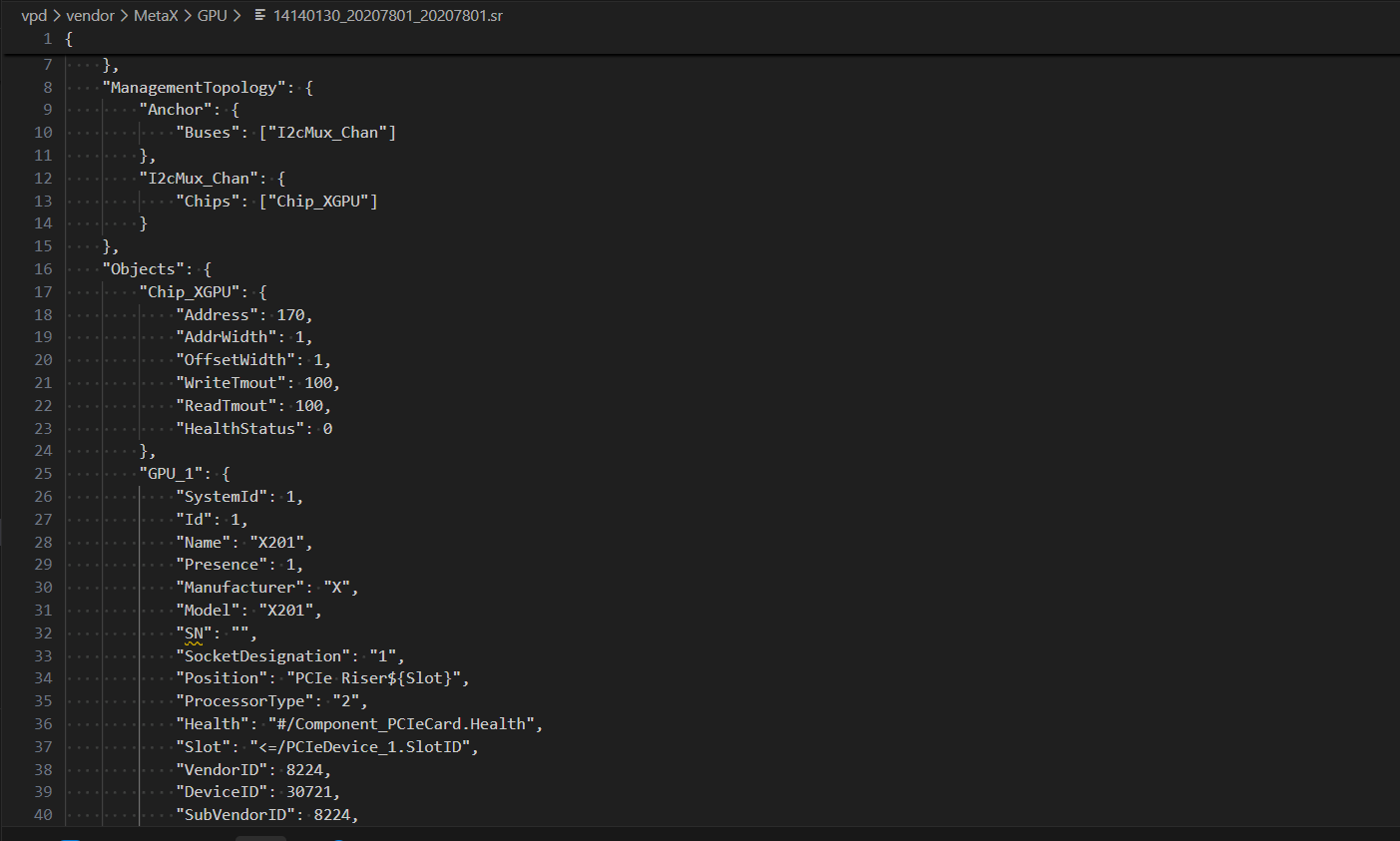
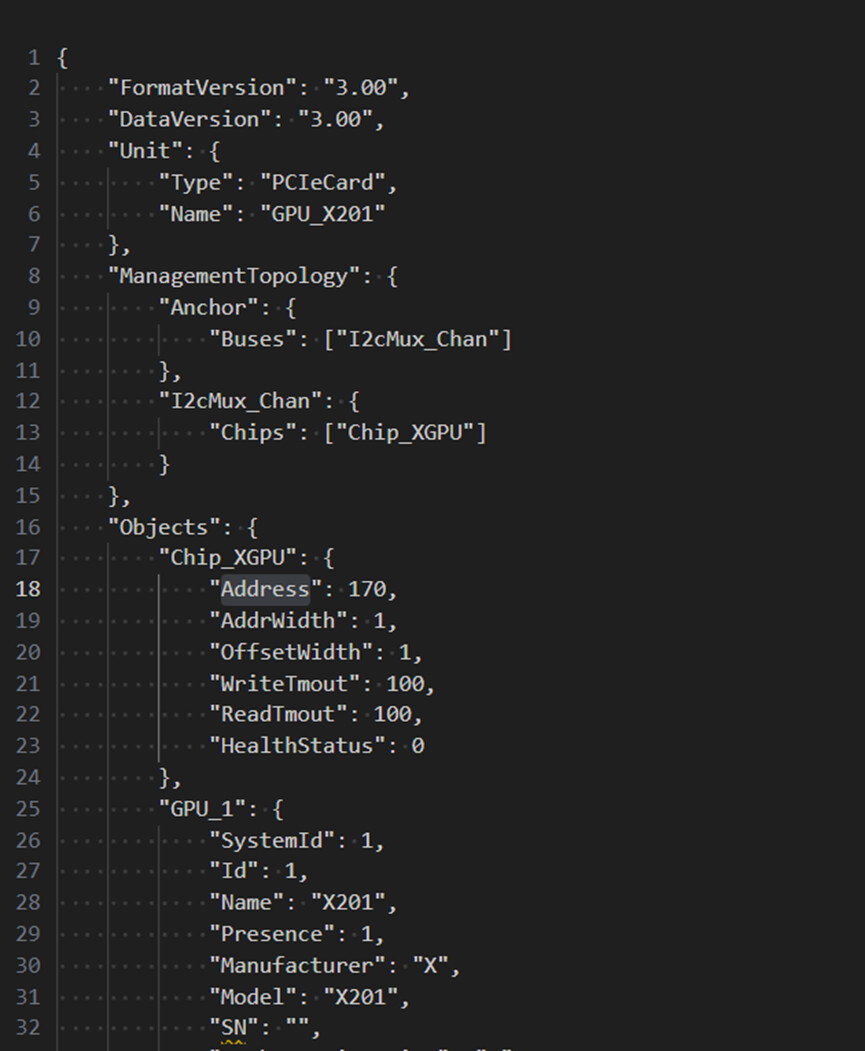
提供一下这个GPU相关的Chip等对象配置
14140130_20207801_20207801.sr.txt (11.4 KB)
使用writeread接口已解决