问题描述
执行reboot后,系统启动过程中闪现CPU相关的温度获取失败告警
环境信息
- 软件版本:OpenUBMC2509
重现步骤
-
具体操作步骤/实际结果】
步骤1:执行reboot长稳结束后,手动检查环境日志(有CPU相关告警上报)步骤2:reboot长稳日志检查(有CPU相关告警上报)
步骤3:一键收集日志检查(有CPU相关告警上报)
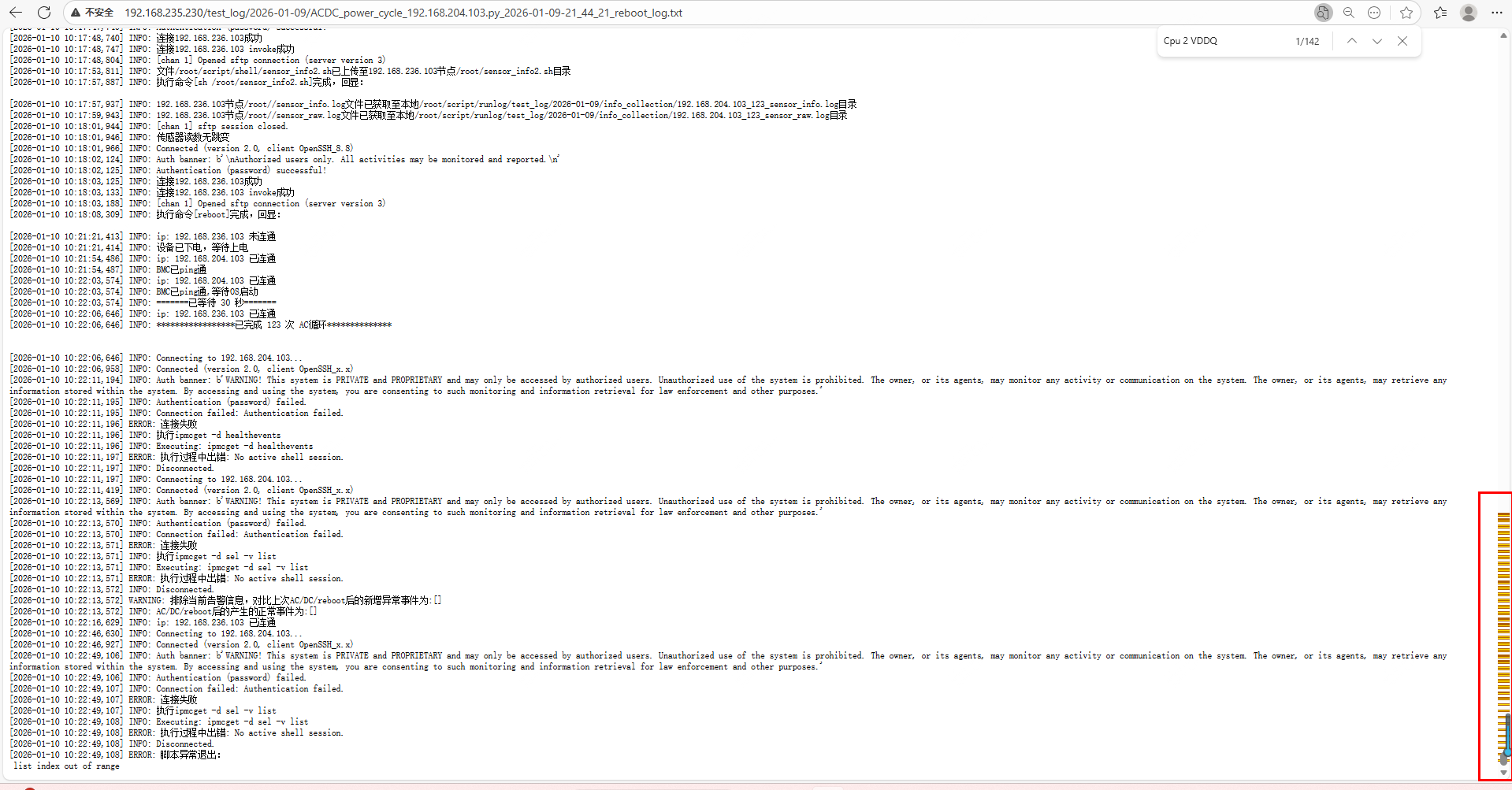
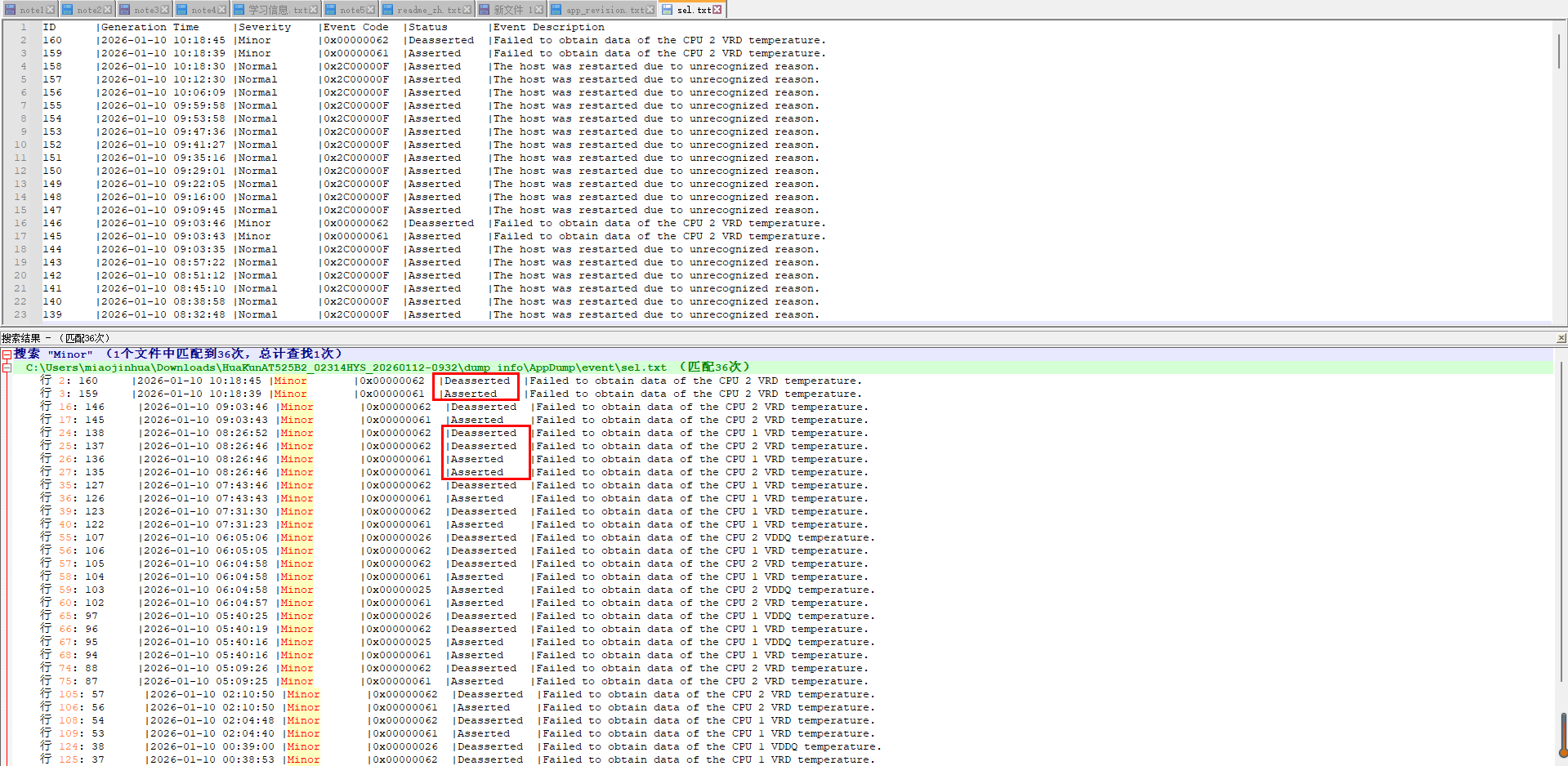
期望结果
没有告警
实际结果
产生VRD和VDDQ告警
尝试过的解决方案
加powergood判断
执行reboot后,系统启动过程中闪现CPU相关的温度获取失败告警
具体操作步骤/实际结果】
步骤1:执行reboot长稳结束后,手动检查环境日志(有CPU相关告警上报)
步骤2:reboot长稳日志检查(有CPU相关告警上报)
步骤3:一键收集日志检查(有CPU相关告警上报)没有告警
产生VRD和VDDQ告警
加powergood判断
答案内容由AI生成,仅供参考:
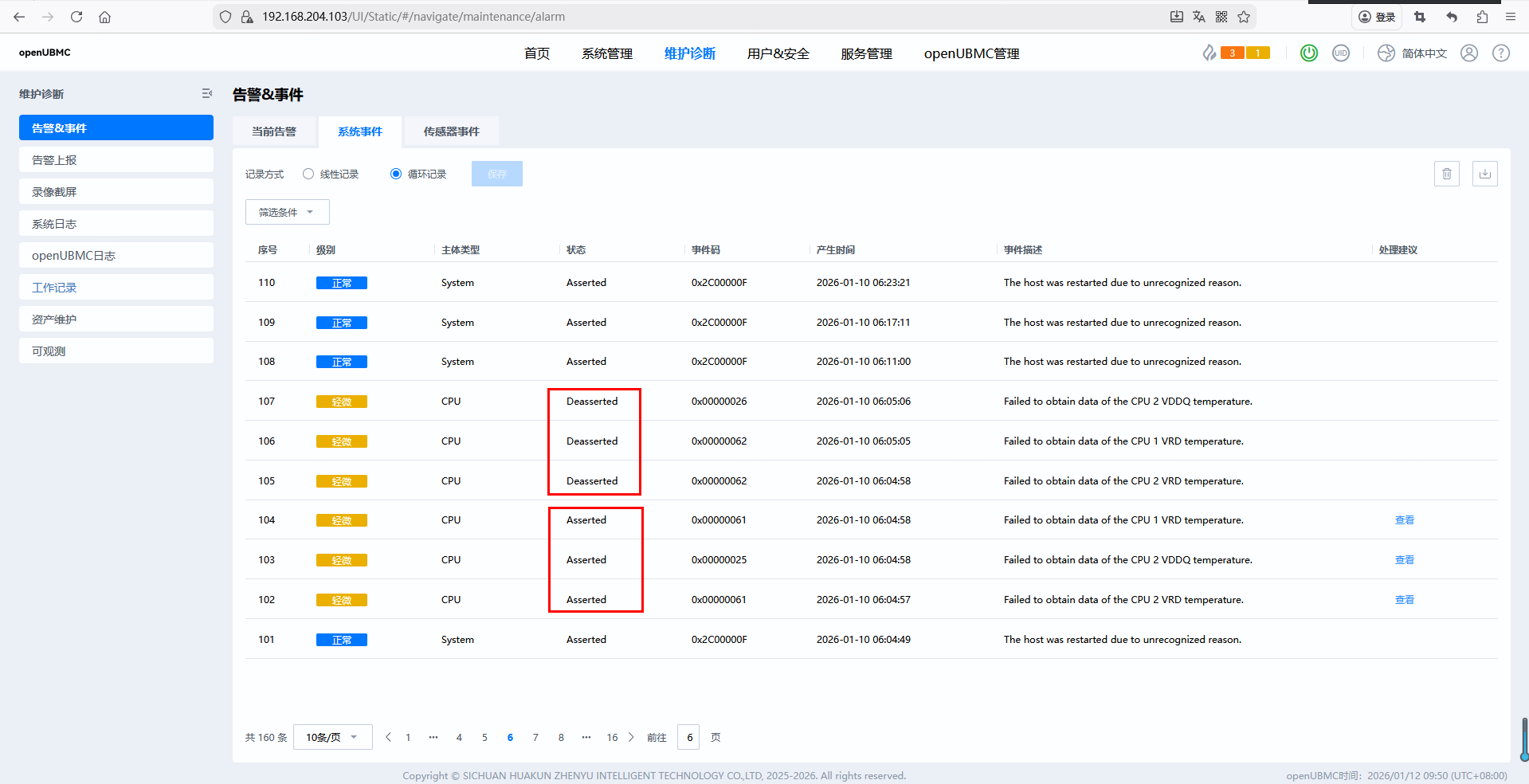
在执行 reboot 指令后,系统启动过程中,BMC 日志中短暂出现 CPU VRD(Voltage Regulator Device)和 VDDQ 温度读取失败的“轻微”级别告警。这些告警随后被自动消除(Deasserted),但在事件日志中仍被记录。
Failed to obtain data of the CPU 1 VRD temperatureFailed to obtain data of the CPU 2 VRD temperatureFailed to obtain data of the CPU 2 VDDQ temperature| 项目 | 内容 |
|---|---|
| 软件版本 | OpenUBMC 2509 |
| 操作系统 | Linux-based Host OS |
| 硬件平台 | 支持双 CPU 架构的服务设备 |
| 日志来源 | BMC Web UI、SEL 日志、一键日志包(event.db / sel.txt) |
根据提供的日志截图与内容,整理关键事件如下:
| 事件码 | 级别 | 事件描述 | 状态 | 产生时间 |
|---|---|---|---|---|
0x00000061 |
轻微 | Failed to obtain data of the CPU 2 VRD temperature | Asserted → Deasserted | 2026-01-10 06:04:57/58 |
0x00000062 |
轻微 | Failed to obtain data of the CPU 1 VRD temperature | Asserted → Deasserted | 2026-01-10 06:04:58 |
0x00000025 |
轻微 | Failed to obtain data of the CPU 2 VDDQ temperature | Asserted → Deasserted | 2026-01-10 06:04:58 |
0x00000026 |
轻微 | Failed to obtain data of the CPU 1 VDDQ temperature | Deasserted | 2026-01-10 06:05:06 |
结论:所有告警均发生在主机重启(
The host was restarted...)前后约 10 秒内,且均被Deasserted,属于瞬态现象。
结合知识库中的实体关系、代码配置逻辑以及防抖机制设计,可以得出以下结论:
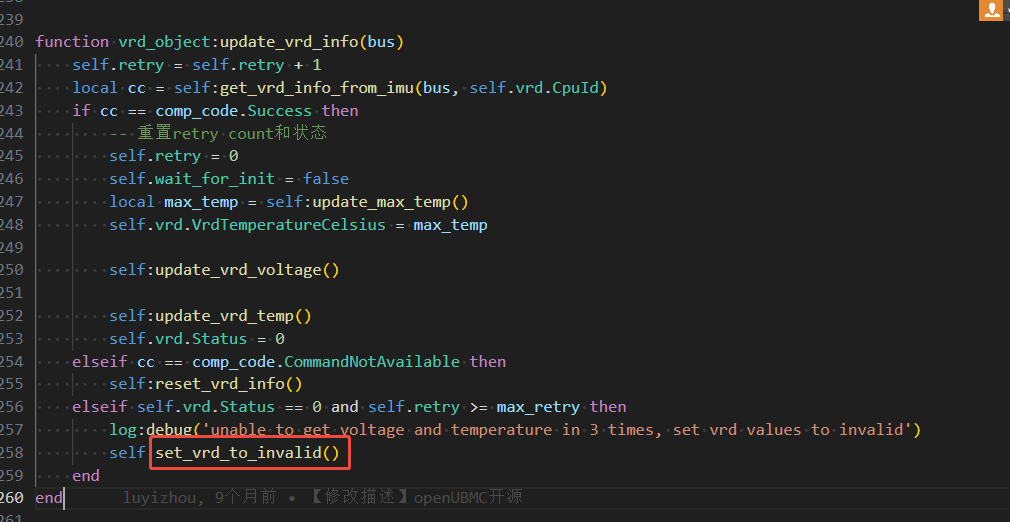
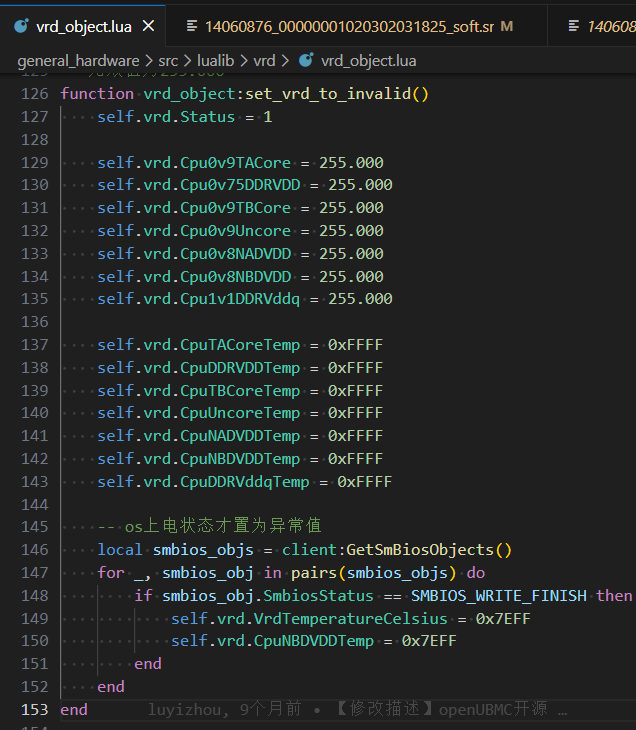
VRD 温度监控对象:
VrdTemperatureCelsiusVrdMgmt 类的软件属性,由 vr_manager.lua 通过 IPMI 协议从 IMU 获取。Chip_CpuIvrd3_01010109 Scanner_CpuIvrem345_vrdTemp_01010109VDDQ 温度监控对象:
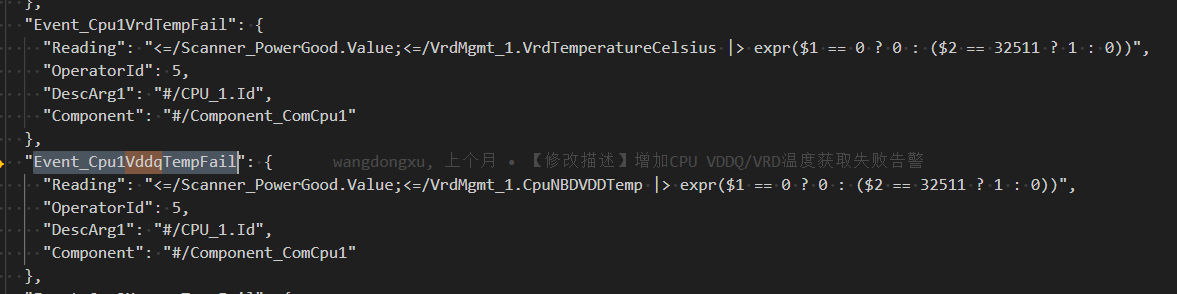
CpuDDRVddqTempCpuNBDVDDTempVrdMgmt 对象下的温度参数,监控 CPU 内存供电模块的温度。VrdMgmt 类定义了这些属性。从提供的 JSON 片段可见,已尝试通过增加 PowerGood 判断 修改事件触发条件:
"Event_Cpu1VrdTempFail": {
"Reading": "<?>Scanner_PowerGood.Value;<?>/VrdMgmt_1.VrdTemperatureCelsius |> expr{$1 == 0 ? 0 : ($2 == 32511 ? 1 : 0)}",
...
}
Scanner_PowerGood.Value == 1(即系统处于上电稳定状态)时,才检查温度值。VrdTemperatureCelsius == 32511(无效值或读取失败),则上报告警。尽管加入了 PowerGood 判断,但以下因素仍可能导致闪现告警:
| 因素 | 说明 |
|---|---|
Scanner_PowerGood 信号的更新可能滞后于温度采集任务的执行周期,导致短暂窗口期内进行无效读取。 |
|
| 温度扫描器周期为 3000ms,而 PowerGood 检测为 8000ms,可能存在竞争条件。 | |
| CPU VRD/VDDQ 温度传感器依赖 BIOS 上报或 VRD 芯片初始化完成,在 reboot 初期尚未就绪。 | |
当前事件未启用 contbin_H10L5 类型的二值防抖(专用于温度读取失败),导致瞬态错误直接触发告警。 |
参考文档:
搜索结果中提及contbin_H10L5用于 “CPU温度读取失败”、“VRD温度读取失败” 等场景。
应在事件定义中引入 持续二值防抖 contbin_H10L5,确保仅在连续多次检测失败后才上报告警。
配置建议:
Event_Cpu1VrdTempFail:
Debounce: "#/Debounce_contbin_H10L5"
Reading: "<?>Scanner_PowerGood.Value; ... "
原理:即使某次读取失败,只要在 10 次高电平判断中不超过 5 次失败,就不会触发告警。
优化表达式,增强判空和状态联动:
"Reading": "<?>Scanner_PowerGood.Value; <?>/VrdMgmt_1.VrdTemperatureCelsius |> expr{$1 != 1 ? 0 : ($2 == 32511 || $2 < 0 ? 1 : 0)}"
$1 != 1 ? 0:非上电状态一律不告警。$2 < 0:补充对负值或异常值的过滤。利用 The host was restarted 这类事件作为上下文,在重启完成前静默特定告警。
if last_event.code == 0x2C00000F and time_since_event < 15s then
suppress_event("CPU_VRD_TEMP_FAIL")
end
已有类似问题在后续版本中被修复(见 search result #4):
“10月版本已解决”
建议确认当前版本 OpenUBMC2509 是否包含相关修复补丁。若未包含,应提交至维护团队考虑合入。
| 项目 | 内容 |
|---|---|
| 问题本质 | 系统重启过程中,因传感器未就绪与监控策略未充分防抖,导致 CPU VRD/VDDQ 温度读取失败告警短暂上报。 |
| 是否真实故障 | |
| 根本原因 | 1. 传感器初始化晚于监控采集 2. 缺少有效防抖机制 3. PowerGood 判断存在窗口期 |
| 推荐措施 | 立即生效: • 增加 contbin_H10L5 防抖• 优化事件触发表达式 长期规划: • 升级至已知修复版本 |
| 实体 | 类型 | 描述 |
|---|---|---|
VrdTemperatureCelsius |
软件属性 | VRD 温度值,用于调速与告警 |
CpuDDRVddqTemp |
软件属性 | CPU DDR VDDQ 区域温度 |
CpuNBDVDDTemp |
软件属性 | CPU NB DVDD 区域温度 |
Scanner_PowerGood |
Scanner | 检测系统是否处于稳定供电状态 |
VrdMgmt |
CSR Class | VRD 电源与温度管理核心类 |
contbin_H10L5 |
防抖机制 | 用于温度读取失败的持续二值防抖 |
参考文档:
- 《CSR配置字典之VrdMgmt类》
- 《CSR硬件监控防抖机制》
- 《CoolingRequirement类配置字典》
![]() 建议闭环操作:
建议闭环操作:
将本次分析结果同步至研发团队,并推动将 Event_CpuXxxTempFail 类事件统一加上 contbin_H10L5 防抖机制,从根本上杜绝重启过程中此类“误报”问题。
相关链接:
app.log中 event会记录告警产生与恢复时的告警值
可以根据这个日志看当时的值是什么 为什么告警
2026-01-24 04:21:08.866263 event NOTICE: hardware_event.lua(580): Event_Cpu1VddqTempFail_010102|{“source”:{“expressions”:[“expr($1 == 0 ? 0 : ($2 == 32511 ? 1 : 0))”],“properties”:[{“Property”:“Value”,“Interface”:“bmc.kepler.Scanner”,“Path”:“/bmc/kepler/Scanner/Scanner_PowerGood_010102”,“Service”:“bmc.kepler.hwproxy”},{“Property”:“CpuNBDVDDTemp”,“Interface”:“bmc.kepler.Systems.VrdMgmt”,“Path”:“/bmc/kepler/Systems/1/VrdMgmt/VrdMgmt_1_010102”,“Service”:“bmc.kepler.general_hardware”}]},“value”:[1,32511],“type”:“synchronization”}
不是这个 你直接过滤这一块的日志截图吧
app.log.txt (2.1 MB)
告警时间大概是2026-01-24 04:21:08
[Event_Cpu1VddqTempFail_010102]generate an event [deassert] while reading change to [0]
[Event_Cpu1VddqTempFail_010102] generate an event [assert] while reading change to [1]
你这边看下 为什么是这个值
这个值就是你的配置传递过来的
可以结合appdump/event 下的 sync_property 文件看
这个告警是与imu通信失败,导致拿不到电源信息。需要找bios分析对应时间点,是否imu有异常,后续恢复通信后才上报数据
sync_property_trace.log.txt (701.4 KB)
看这两个值是否符合预期

符合的,powergood是电源状态,1是上电,温度能获取40度
我的意思是 指在0 和 1 之间变更的时候 就会产生告警和消除告警
你在结合上面app.log 日志的时间
如果认为当时的值不应该是0/1
再分析那个时间段的值
这跟告警无关了 要看告警配置了
那估计就是你环境上生效的SR的问题了
收集一下日志吧
麻烦提供一下邮箱呢