基于2509的openUBMC构建的版本
AC和强制重启时,应该是因为GPU芯片还没准备好,因此会出现类似0这样的异常温度读值。但是又不能对0这种读值完全过滤,万一真的异常是要报出来的。
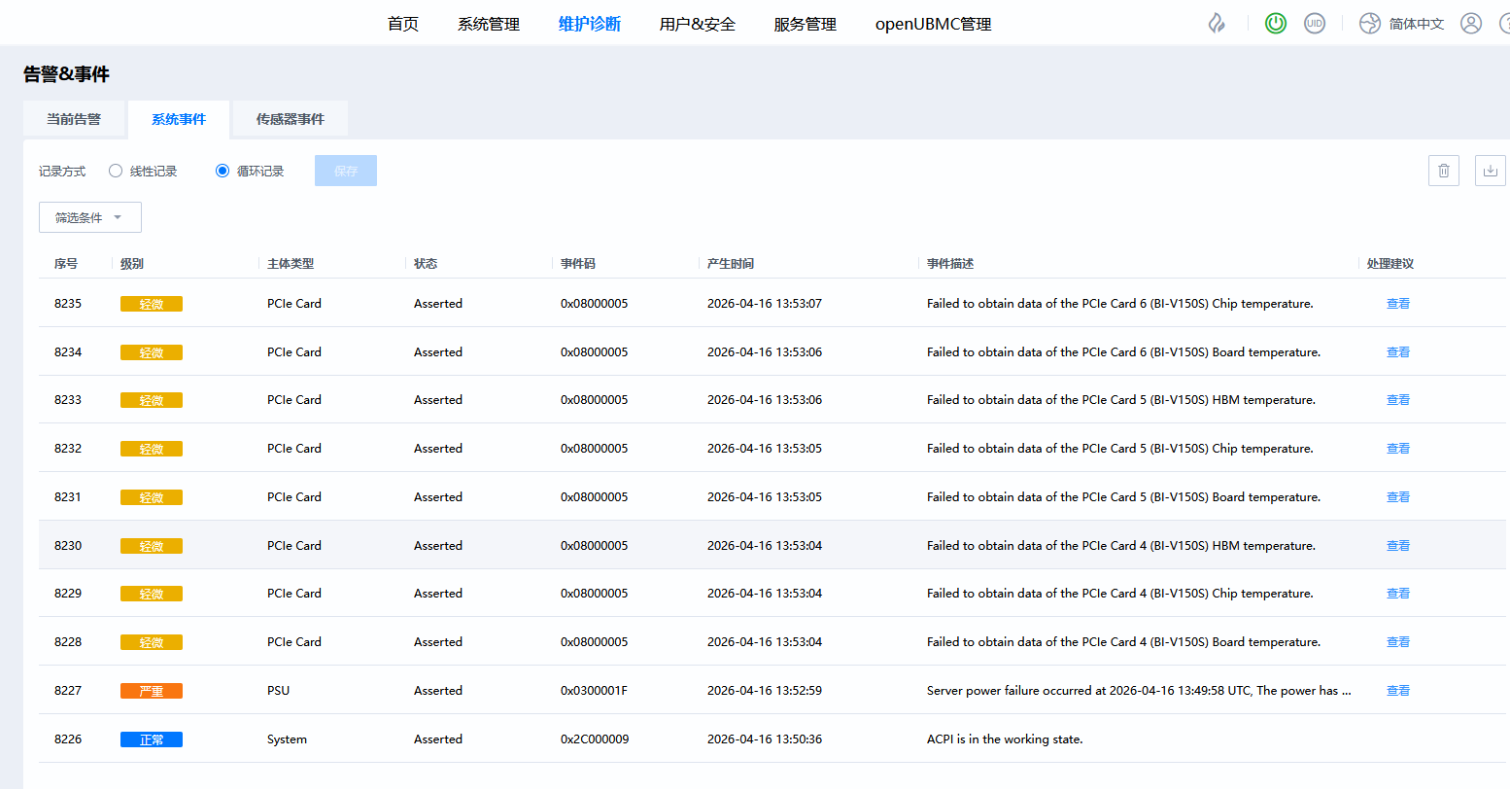
为了区分这种正常情况和异常情况,openUBMC中有没有类似post complete的机制,即OS启动完成,这种情况下GPU应该都准备好了,不会再出现这种误告警。
基于2509的openUBMC构建的版本
AC和强制重启时,应该是因为GPU芯片还没准备好,因此会出现类似0这样的异常温度读值。但是又不能对0这种读值完全过滤,万一真的异常是要报出来的。
为了区分这种正常情况和异常情况,openUBMC中有没有类似post complete的机制,即OS启动完成,这种情况下GPU应该都准备好了,不会再出现这种误告警。
答案内容由AI生成,仅供参考:
| 项目 | 建议 |
|---|---|
| 是否支持“Post Complete”机制 | OS Startup State 可用作等效替代 |
| 是否应过滤 0 值温度 | |
| 短期缓解措施 | 配置传感器读取失败防抖(如连续失败 5 次再告警) |
| 长期根本解决方案 | 利用 OS Startup State 或 GPU 就绪信号作为告警使能条件 |
| 验证方法 | 使用“一键收集日志”分析 event、app.log、sensor 数据 |
建议行动项:
- 在当前 25.09 版本中,优先配置 GPU 相关传感器的 防抖机制。
- 推动将
OS Startup State集成到 Event 管理框架中,实现基于系统状态的动态告警控制。- 在后续版本(如 OpenUBMC 26.03)中,将此类启动瞬态告警问题纳入 通用观察点测试项,防止回归。
在基于 OpenUBMC 25.09 构建的系统中,用户反馈在 AC上电(通断电) 或 BMC 强制重启 后,系统频繁上报 GPU/Pcie卡温度获取失败告警(事件码 0x08000005),提示“Failed to obtain data of the PCIe Card X (XX) Chip/Board/HBM temperature”。
此类现象在系统启动初期较为常见,其本质是 硬件初始化时序未完成 导致的 瞬态/误告警(Transient Alert),而非真实硬件故障。本文结合 openUBMC 的机制、社区实践和可靠性设计原则,分析此问题的成因,并探讨可行的解决方案。
GPU 芯片初始化滞后
事件机制未区分“启动阶段”与“稳定运行”
告警处理策略不足
典型问题表现:
- 告警集中在
AC或BMC Restart后几秒内集中爆发。- 数分钟后自动恢复(Deassert),无真实硬件更换。
- 一键日志中可看到相关 PCIe 卡的 BDF 信息上报延迟、MCU 初始化日志滞后。
目前 OpenUBMC 尚未提供完全等同于传统 iBMC 中“Post Complete” 的标准全局信号,但已具备实现该功能的技术基础与组件机制:
OS Startup State 作为全局属性已存在于 OpenUBMC 系统模型中。{"entity1": "OS Startup State", "entity2": "openUBMC", "description": "The openUBMC system requires a global attribute to represent the OS startup state for accurate sensor event triggering."}
cpu_board.lua 等脚本监控关键系统状态:-- 示例:cpu_board.lua 检查 BMC 启动完成标志
if get_bmc_start_flag() then
notify_system_ready()
end
median_s5、midavg_s4 等滤波算法。为解决 AC/强制重启后 GPU 温度误告警问题,建议从 “状态感知” 与 “告警抑制” 两个维度入手:
定义系统准备就绪信号
OS Startup State 属性,由主机通过 IPMI Set System Boot Options 命令或 Redfish ResetType: On 后的状态反馈置位。compute 模块)上报“PCIe 枚举完成”、“GPU MCU Ready”事件。配置 Event 规则依赖此状态
IF OS_Startup_State == Completed THEN
ENABLE Alert for GPU_Temp_Fail
ELSE
IGNORE or LOG without Alerting
ENDIF
优势:
为 GPU 温度传感器配置防抖参数
contbin 配置,设定 连续失败次数阈值(如 5 次) 和 检测周期(如 10s)。结合启动窗口期抑制(Startup Suppression)
Event 模块配置 suppression_window=60s 实现。优势:
app.log、dmesg_info 中 GPU/MCU 初始化时间线。ipmitool raw 0x30 0x90 或 ReportPcieCardBDFInfoToBMC 接口确认 BDF 上报延迟情况。compute、vpd、fru 等组件的启动顺序是否影响 GPU 识别。类似问题已存在多个案例:
Topic 5325:SLOT2 NPU 卡温度丢失,重启 openUBMC 恢复。Topic 5028:AC 长稳偶现 CPU/内存温度获取失败,初步定位为 ipmb 通道注册延迟。Topic 5821:AC 掉电事件日志记录不全,涉及电源事件丢失。AI助手 ubmc_assistant 的建议倾向:
| 项目 | 建议 |
|---|---|
| 是否支持“Post Complete”机制 | OS Startup State 可用作等效替代 |
| 是否应过滤 0 值温度 | |
| 短期缓解措施 | 配置传感器读取失败防抖(如连续失败 5 次再告警) |
| 长期根本解决方案 | 利用 OS Startup State 或 GPU 就绪信号作为告警使能条件 |
| 验证方法 | 使用“一键收集日志”分析 event、app.log、sensor 数据 |
- 在当前 25.09 版本中,优先配置 GPU 相关传感器的 防抖机制。
- 推动将
OS Startup State集成到 Event 管理框架中,实现基于系统状态的动态告警控制。- 在后续版本(如 OpenUBMC 26.03)中,将此类启动瞬态告警问题纳入 通用观察点测试项,防止回归。
如需进一步技术支持,可访问 OpenUBMC 论坛相关讨论:
尝试增加时延或者询问硬件厂商是否有心跳检测机制